
AI: The Big Tech war — comparing OpenAI, Meta, Google, and Mistral LLMs
As of now, GPT-4-Turbo currently leads in the LMSYS Chatbot Arena, closely followed by Anthropic’s Claude 3 Opus, with Meta’s open-source Llama 3 outperforming all of Mistral’s models
Hi Fintech Futurists —
Today we highlight the following:
AI: The Evolution of LLMs Through Meta's Llama 3, OpenAI's GPT-4-Turbo, Mistral's Mixtral 8x22B, and Google's Gemini 1.5
LONG TAKE: Lessons from Petal's sale to Empower, after nearly $1B in capital raised
PODCAST: Betterment's path to $45B and beyond, with CEO Sarah Levy
CURATED UPDATES: Machine Models, AI Applications in Finance, Infrastructure & Middleware
To support this writing and access our full archive of newsletters, analyses, and guides to building in the Fintech & DeFi industries, subscribe below. Only $12/month.
AI: The Evolution of LLMs Through Meta's Llama 3, OpenAI's GPT-4-Turbo, Mistral's Mixtral 8x22B, and Google's Gemini 1.5
Within the financial sector, the application of machine learning models, particularly Large Language Models (LLMs), is transforming how data is analyzed, decisions are made, and customer interactions are managed. The economic implication of this is trillions in new GDP growth, with $200 to $400 billion of productivity impact on banks.
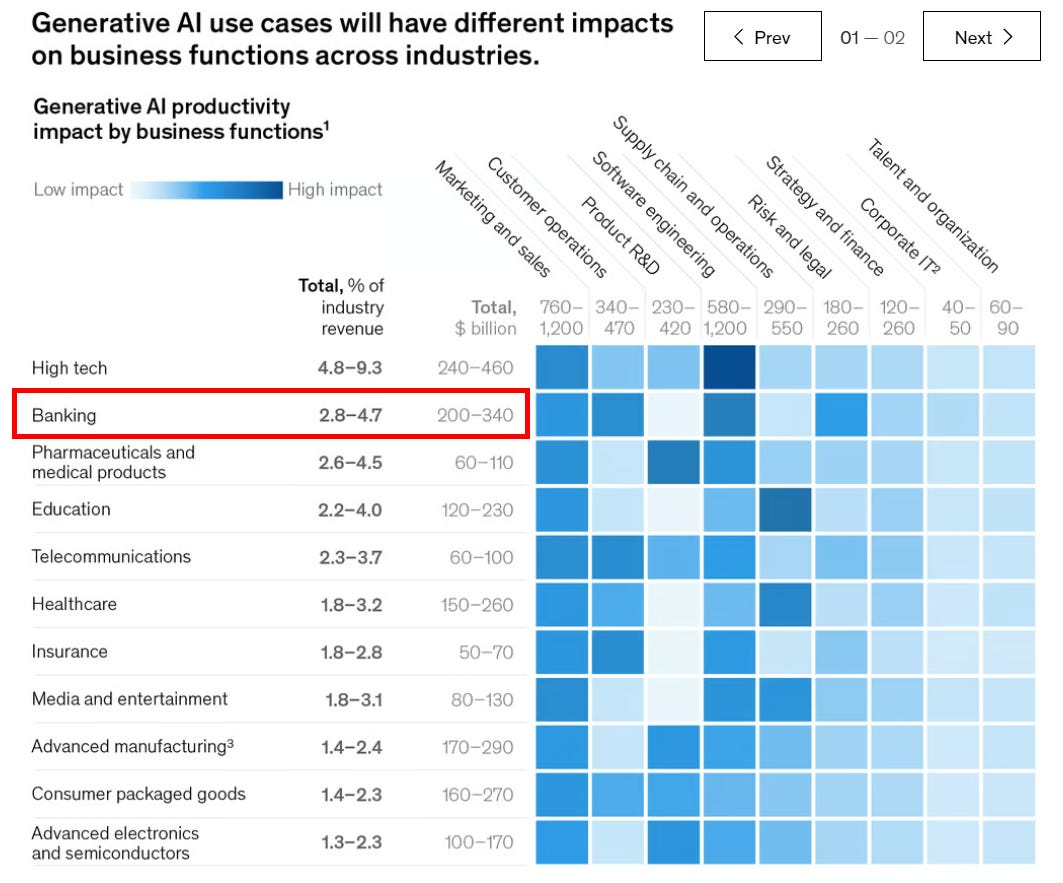
This process is now in progress. Below, we parse the technical evolution and capability of what AI models can deliver. Over the last decade, the development of AI models has shifted dramatically from (1) academic institutions, where research thrives to (2) industry corporate leaders, where commercialization can happen.

In 2023, industry players developed over three times the number of significant machine learning models compared to academia, a gap that continues to widen into 2024. This transition is not only a testament to the growing complexity and capability of these models — such as Meta's Llama 3, Mistral AI's Mixtral 8x22B, OpenAI's GPT-4-Turbo, and Google's Gemini 1.5 — but also highlights the increasing computational costs and the capital-intensive nature of AI research and development.

You have to pay to train.
Bit Tech Brains
Meta’s latest release, Llama 3, introduces Grouped Query Attention (GQA), which reduces the computational complexity associated with processing large sequences by clustering attention queries. This allows the model to “focus” attention queries in groups, which speeds things up and improves the handling of larger datasets.
Llama 3 also had extensive pre-training involving over 15 trillion tokens, including a significant amount of content in different languages, enhancing its applicability across diverse linguistic contexts. For post-training techniques, Meta used supervised fine-tuning and rejection sampling to refine the model's ability to follow instructions and minimize error rates.
Currently, Meta offers two Llama 3 models: the 8B and 70B, with 8 billion and 70 billion parameters, respectively. And later this year, they're set to release its largest version, the Llama 3 400B.

Mistral AI's Mixtral 8x22B employs a Sparse Mixture-of-Experts (SMoE) architecture, which maximizes efficiency by activating only a fraction of its total parameters — 39 billion out of a theoretical 141 billion — depending on the task. The model's architecture ensures that only the most relevant “experts” are activated during specific tasks. This is good for coding and multilingual translation.
Note that “experts” are individual neural networks that are part of a larger system (i.e., the SMoE model). These experts are trained to become highly proficient at particular sub-tasks within the overall task. The “sparse” part of SMoE means the activation of experts is limited. Typically only a few experts are engaged for any given input, reducing computational load.


Similarly, Google’s Gemini 1.5 Pro leverages a Mixture-of-Experts (MoE) architecture, which helps the model to process large datasets by activating relevant neural network segments. Unlike Sparse MoE models, Gemini 1.5 does not rely on stringent gating mechanisms, allowing for a more flexible expert activation process.
The standout feature of the Gemini upgrade is its ability to manage up to 1MM tokens — equivalent to 700,000 words, one hour of video, or 11 hours of audio. And it can manage up to 10MM tokens in research. This level of scale sets a whole new benchmark among LLMs and shows Google’s firepower.

Of course, OpenAI is well aware of this, and in response, GPT-4-Turbo significantly enhances its multimodal capabilities by incorporating AI vision technology. This allows the model to analyze videos, images, and audio. Additionally, the model's tokenizer now has a larger 128,000 token context window — meaning it remembers more of the things you tell it.

Cost of Training
There is an exponential increase in parameters with each new release of LLM generations. This runs opposite to a foundational principle of econometrics called parsimony — using a minimum number of parameters necessary to adequately represent data, thereby preventing overfitting and improving the model's performance on new, unseen data. However, the growing parameter counts in models like GPT-4 (1.7T parameters) suggest a departure from this traditional approach.
Even in financial machine learning, basic equity return neural network models are equipped with tens of thousands of parameters. Traditionally, such heavy parameterization might be viewed as excessive, raising concerns about overfitting and potentially poor out-of-sample performance. Yet, the latest results from various non-financial domains such as computer vision and natural language processing tell a different story. Models with large numbers of parameters that are tightly fitted to their training data often outperform their more parsimonious counterparts when tested on new data.
“It appears that the largest technologically feasible networks are consistently preferable for best performance.” - Mikhail Belkin


But the increasing number of parameters in LLMs has driven up training costs, making the field more capital-intensive due to the high demand for GPUs. For example, Sam Altman noted that training GPT-4 exceeded $100MM.
This surge in expenses has marginalized traditional research centers from developing foundation models due to financial constraints. Consider the evolution over the past years — the original Transformer model, pivotal in modern LLM development, cost merely $900 to train in 2017. By 2019, the training cost for RoBERTa Large, which set new benchmarks on comprehension tests, escalated to about $160,000. Fast forward to 2023, the estimated training expenses for Google's Gemini Ultra soared to $191MM.
To address the growing divide between industry and academia in AI, there have been policy responses like President Biden’s Executive Order to set up a National AI Research Resource. In our opinion, the overwhelming private investment in this sector poses challenges for academia to keep pace with the top industry players.
Future Model Features
Looking ahead in the development of LLMs, Google's Gemini provides a clear indication of the future trajectory:
Multimodality: Future LLMs are expected to be multimodal, capable of processing and understanding various data forms — text, images, videos, and audio. The GPT-4-Turbo upgrade focuses on this as well. And Gemini 1.5’s upgrade sets a new standard with its 1MM token context window, which other players will want to reach.

Recall Capability: Consider the Claude 2.1 AI model with its 200,000-token window, which struggles with the Needle in a Haystack test — designed to test a model's ability to retrieve specific information from a large dataset. For instance, if you previously shared your phone number with Claude 2.1, it might fail to recall it later, especially as the document length increases.


In contrast, Gemini 1.5 Pro retrieves "needles" with over 99% accuracy from a "haystack" of millions of tokens across text, video, and audio, maintaining this performance even at the scale of 10MM tokens.


Reasoning: Beyond recalling information, reasoning is the next frontier. This involves not just retrieving information, but synthesizing it to form a deeper understanding and making informed decisions. Have you ever given ChatGPT 3.5 some information to analyze, only to get a very basic summary in return? This is what we mean by reasoning, and it will become an increasingly important measure of how advanced LLM models are.
With these recent advancements, fintechs and other financial companies seeking to leverage LLMs find themselves at a crossroads.
On one hand, the development and training of LLMs have escalated to costs that are prohibitive for most companies. On the other hand, open-source models like Llama 3 have advanced to surpass many proprietary models, allowing companies to implement their own LLM without the exorbitant cost.
This suggests that the capital gains for financial companies are not in the creation of the model itself, but in the tuning of the open-source big-tech machine minds on proprietary data sets and use cases. The war for AI is a benefit to the industries that want to employ it.
👑 Related Coverage 👑



Blueprint Deep Dive
Long Take: Lessons from Petal's sale to Empower, after nearly $1B in capital raised (link here)
In this article, we discuss the financial and operational challenges faced by Petal, a fintech company aiming to innovate in the credit sector by using non-traditional underwriting methods, and its acquisition by Empower Finance.

Despite raising significant funds, Petal and similar fintech endeavors like Empower Finance, which pivoted to cash advances, and Elevate Credit, which eventually was acquired at a fraction of its peak valuation, illustrate the harsh realities of lending-based business models. The lending sector, attractive for its upfront revenue, is fraught with risks of high defaults and regulatory challenges. We conclude that while fintech can reduce transactional frictions, it cannot alone solve the deeper economic issues that lead to financial distress for many consumers.
🎙️ Podcast Conversation: Betterment's path to $45B and beyond, with CEO Sarah Levy (link here)
In this conversation, we chat with Sarah Levy - CEO of Betterment, the largest independent digital investment advisor.

Sarah brings over 25 years of brand building, customer loyalty, corporate strategy and operational excellence to her role, and she has a passion for taking businesses to the next level.
Curated Updates
Here are the rest of the updates hitting our radar.
Machine Models
⭐ In Deep Reinforcement Learning, a Pruned Network is a Good Network - Johan Obando-Ceron, Aaron Courville, Pablo Samuel Castro
⭐ The EU AI Act and general-purpose AI - TaylorWessing
The Looming Crisis of Web-Scraped and Machine-Translated Data in AI-Language Training - Appen
Can Machines Understand Human Skills? Insights from Analyst Selection - Sean Cao, Norman Guo, Houping Xiao, Baozhong Yang
Algorithmic Collusion by Large Language Models - Sara Fish, Yannai A. Gonczarowski, Ran I. Shorrer
AI Applications in Finance
⭐ Can ChatGPT Generate Stock Tickers to Buy and Sell for Day Trading? - World Bank
⭐ NeurIPS 2023: Our Favorite Papers on LLMs, Statistical Learning, and More - Two Sigma
The Missing U for Efficient Diffusion Models - Sergio Calvo-Ordonez, Chun-Wun Cheng, Jiahao Huang, Lipei Zhang, Guang Yang, Carola-Bibiane Schonlieb, Angelica I Aviles-Rivero
Deep Limit Order Book Forecasting - Antonio Briola, Silvia Bartolucci, Tomaso Aste
Stable Neural Stochastic Differential Equations in Analyzing Irregular Time Series Data - YongKyung Oh, Dongyoung Lim, Sungil Kim
Navigating Market Turbulence: Insights from Causal Network Contagion Value at Risk - Katerina Rigana, Samantha Cook, Ernst C. Wit
Robust Utility Optimization via a GAN Approach - Florian Krach, Josef Teichmann, Hanna Wutte
Log Neural Controlled Differential Equations: The Lie Brackets Make a Difference - University of Oxford, City University of Hong Kong
Infrastructure & Middleware
⭐ Introducing Our Next Generation Infrastructure for AI - Meta
Macquarie Leads $500 Million Loan for AI Infrastructure Company Lambda - WSJ
Microsoft to invest $2.9B to boost Japanese cloud and AI infrastructure - Total Telecom
Oracle to Invest More Than $8B in Cloud Computing and AI in Japan - Financial Times
🚀 Level Up
Sign up to the Premium Fintech Blueprint and in addition to receiving our free newsletters, get access to:
All Long Takes with a deep, comprehensive analysis on Fintech, Web3, and AI topics.
Archive Access to an array of in-depth write-ups covering the hottest fintech and DeFi companies.
"proprietary data sets", sure, but more importantly "information". So good luck to big tech, little tech, and public sector with all that "monitoring".