
AI: Machine Learning beats ChatGPT in predicting Corporate Credit Risk (for now)
Regulation is increasingly prioritizing explainability alongside absolute performance.
Hi Fintech Futurists —
Today we highlight the following:
AI: Traditional XGBoost machine learning model outperforms GPT-4o in credit risk prediction
LONG TAKE: Why credit fintech Tally burned through $170MM and still failed
PODCAST: Pipe's Pivot from Revenue Exchange to Digital Lending, with CEO Luke Voiles
CURATED UPDATES: Machine Models, AI Applications in Finance, Infrastructure & Middleware
To support this writing and access our full archive of newsletters, analyses, and guides to building in the Fintech & DeFi industries, see subscription options here.
Fintech Blueprint x Brainfood | Happy Hour

Are you based in London and love Fintech? We are planning a get-together for the community on September 10th in partnership with Fintech Brainfood’s Simon Taylor.
Meet us for an evening of Fintech networking, drinks, and nibbles! Would love to see you, register below.
AI: Traditional XGBoost machine learning model outperforms GPT-4o in credit risk prediction
Since ChatGPT went mainstream, the debate over whether large language models (LLMs) can make reliable financial decisions has gained significant attention in both academia and industry.
Previously, we explored how LLMs compare to analysts in financial statement analysis and earnings prediction. Now, their role expanding into areas like credit risk assessment, where 20% of respondents in McKinsey’s “Embracing Generative AI in Credit Risk” survey have already implemented at least one generative AI use case in their organizations.

Credit risk — the probability that a borrower might default — is a major concern for a wide range of financial institutions. Misjudgments in this area can lead to significant financial losses, impacting commercial and investment banks like JPMorgan Chase, insurance companies like AIG, and government-sponsored enterprises like Fannie Mae and Freddie Mac.
Credit ratings from Standard & Poor's, Moody's, and Fitch are the key indicators of a borrower's creditworthiness. These ratings directly influence lending decisions, interest rates, and capital allocation across the financial ecosystem, where institutional investors rely on them to judge risk exposure for their portfolios.

Credit rating downgrades can trigger a cascade of effects, including higher borrowing costs and reduced access to capital markets. For example, during the 2008 financial crisis, AIG's credit rating downgrade exacerbated its liquidity crisis, ultimately leading to a $182B government bailout. Accurately predicting these rating shifts is especially important for funds with strict investment mandates, such as pension funds, which are prohibited from holding subprime or speculative-grade assets.


Predicting credit risk is not a new challenge.
Traditional methods have long involved analyzing financial statements, applying credit scoring models, and assessing collateral. However, these approaches often rely heavily on historical data — overlooking the real-time, dynamic factors that can influence a borrower’s financial condition. The 2008 subprime mortgage crisis serves as a reminder of the consequences of misjudging credit risk.
To try and mitigate such mistakes, machine learning (ML) algorithms have significantly improved credit risk assessment. Among these, Gradient Boosting Machines, particularly XGBoost, have emerged as robust performers. XGBoost iteratively corrects prediction errors, effectively handles imbalanced datasets common in default prediction, and provides feature importance metrics through techniques like SHAP (SHapley Additive exPlanations) values.


But will machine learning be superseded by generative AI?
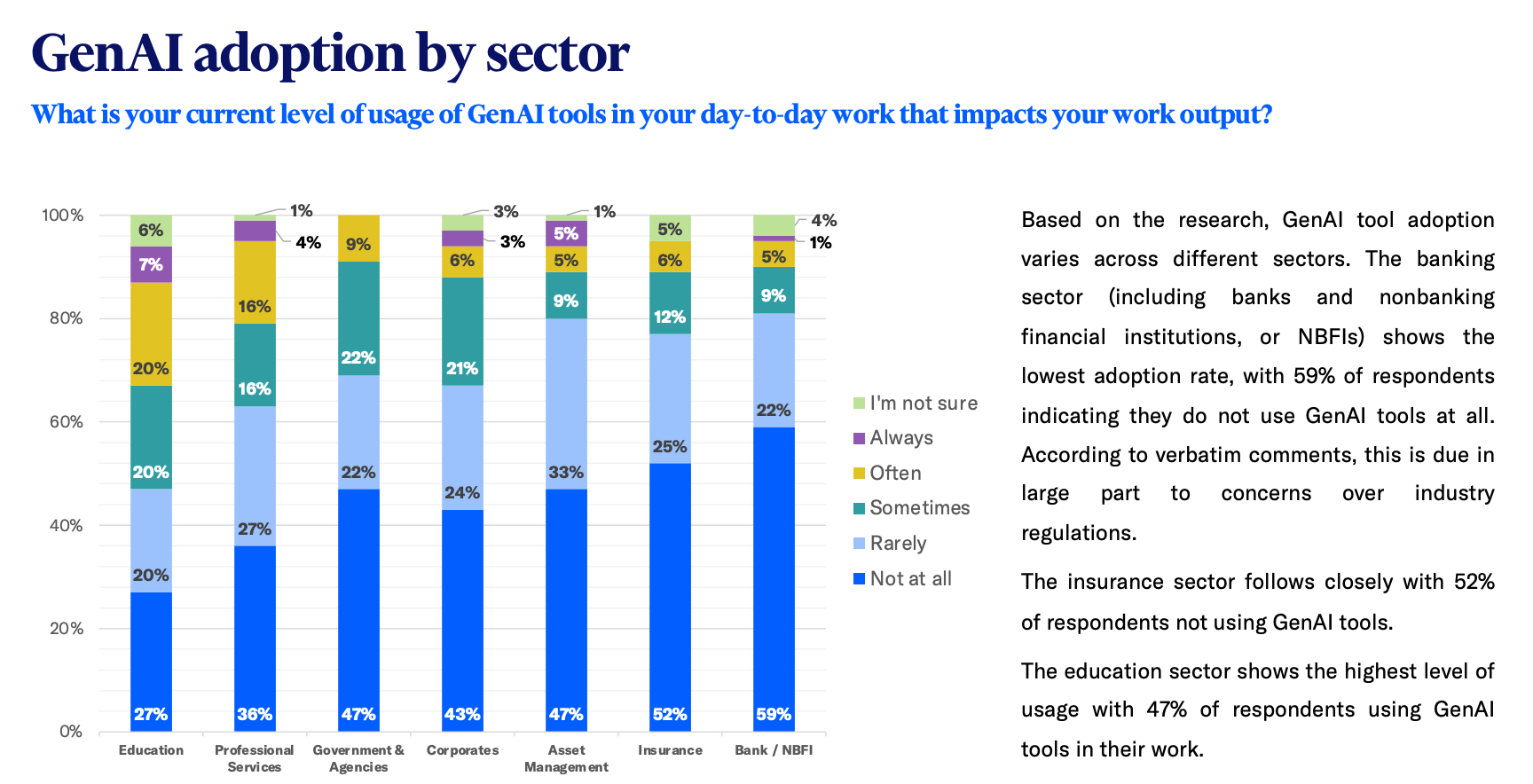
Given that LLMs have shown strong performance across various financial domains, recent studies have begun evaluating their effectiveness in predicting credit rating changes. A recent study by three Oxford University researchers reveals that while LLMs excel at processing textual information, traditional ML methods still outperform them in handling numeric and multimodal data. The study used a dataset covering credit ratings from 1978 to 2017, alongside SEC filings — particularly the Management’s Discussion and Analysis section — and included macroeconomic data like labor statistics and interest rates.

The results show that the XGBoost model achieved an accuracy of 54% across various prediction horizons, surpassing GPT-4o, which, relying solely on text data, achieved 50%. When tasked with integrating both text and numerical inputs, GPT-4o’s accuracy dropped to 40%, highlighting a significant limitation of current LLMs in processing multimodal financial data.
The study also uncovered an interesting complementarity between traditional ML models and LLMs — when combining predictions of XGBoost (using only numerical data) and GPT-4o (using only text), the combined accuracy rose to 70%.
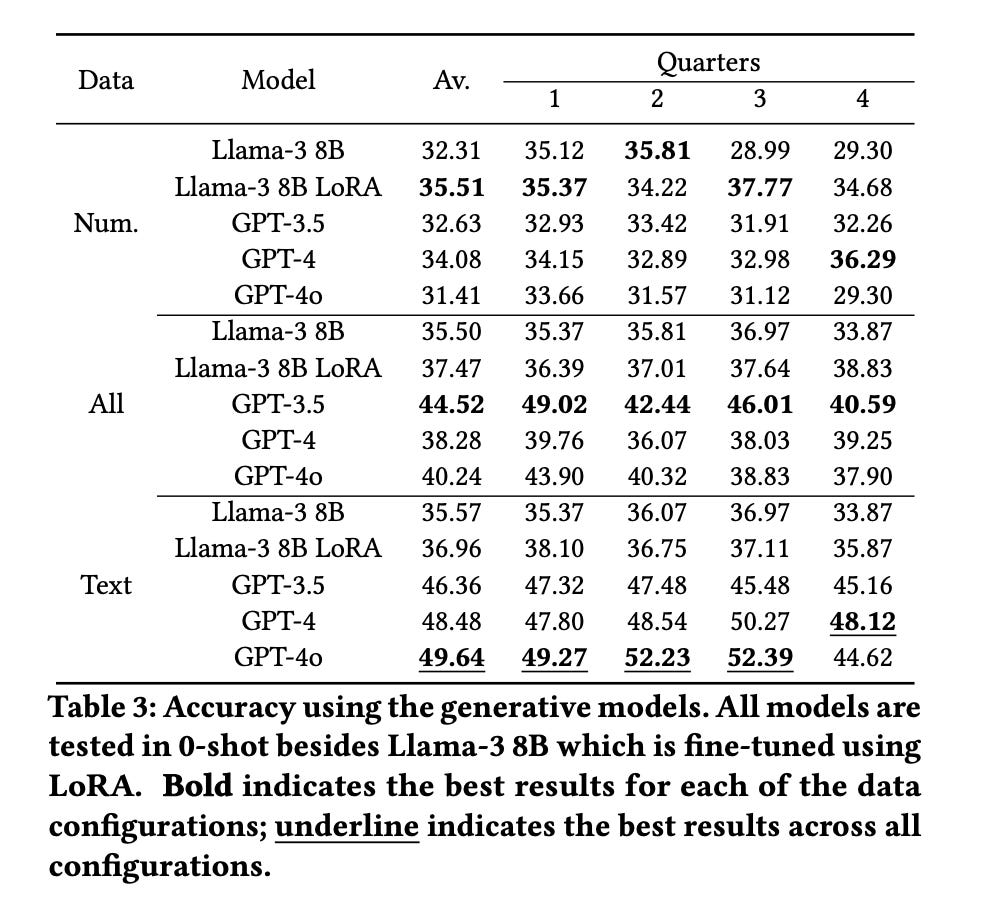

But besides the accuracy, a core point is the importance of interpretability in financial modeling given the current regulatory environment. Based on the study, the XGBoost-Clusters framework provided “end-users with the ability to understand and explain the decisions that made” via partial dependence plots (PDPs). Figure 2 from the study (see below) shows PDPs for two text-based features across different target classes. Specifically, in Figure 2a, we see that the more a company's filing discusses ratings, the lower the likelihood of a credit rating upgrade. Figure 2b shows that as companies mention receivables more often — the money owed to the company — the chance of a credit rating downgrade decreases.


Recently, the Consumer Financial Protection Bureau (CFPB) has taken a firm stance on AI in financial services, requiring that any AI system used for credit rating forecasting be accurate, fair, transparent, and compliant with anti-discrimination laws. Because many LLM models operate as "black boxes," the future of AI in credit risk assessment might hinge on improvements in multimodal learning techniques that can combine different types of data while maintaining *interpretability*. Perhaps the latter will become even more important than performance alone.
We may see the development of ensemble systems that pair the language processing abilities of LLMs with more transparent quantitative models like XGBoost — this approach could potentially meet regulatory standards while making full use of the available data.
👑 Related Coverage 👑



Blueprint Deep Dive
Long Take: Why credit fintech Tally burned through $170MM and still failed (link here)
We examined the rise and fall of Tally, a fintech startup that aimed to help consumers manage and refinance credit card debt. Founded in 2015, Tally raised $172 million and peaked at an $855 million valuation in 2022, but recently shut down due to funding challenges.
We analyzed Tally's business model of consolidating credit card debt and offering lower interest rates, highlighting the lending industry's complexities such as underwriting, capital costs, and economic cycle vulnerabilities. We attribute Tally's downfall primarily to market structure challenges, rising interest rates, and increasing consumer credit delinquencies, rather than industry-wide fintech issues.
🎙️ Podcast Conversation: Pipe's Pivot from Revenue Exchange to Digital Lending, with CEO Luke Voiles (link here)
In this conversation, we chat with Luke Voiles - CEO and Board Member of Pipe, a position he started in February 2023. Prior to this, Luke was the GM of Square Banking at Block where he led the global team responsible for managing, launching, and scaling small business banking and lending products.

Before Square, he was at Intuit, where he led the team in building out the small business lending unit, QB Capital, from scratch. Luke made the switch from private equity to fintech after more than a decade as a distressed asset and credit special situations investor at top-tier funds, including TPG Capital and Lone Star Funds.
Curated Updates
Here are the rest of the updates hitting our radar.
Machine Models
⭐ How to Choose a Reinforcement-Learning Algorithm - Fabian Bongratz, Vladimir Golkov, Lukas Mautner, Luca Della Libera, Frederik Heetmeyer, Felix Czaja, Julian Rodemann, Daniel Cremers
⭐ Representation Learning of Geometric Trees - Zheng Zhang, Allen Zhang, Ruth Nelson, Giorgio Ascoli, Liang Zhao
A survey on secure decentralized optimization and learning - Changxin Liu, Nicola Bastianello, Wei Huo, Yang Shi, Karl H. Johansson
Neural Reward Machines - Elena Umili, Francesco Argenziano, Roberto Capobianco
NEAR: A Training-Free Pre-Estimator of Machine Learning Model Performance - Raphael T. Husistein, Markus Reiher, Marco Eckhoff
Efficient Multi-Policy Evaluation for Reinforcement Learning - Shuze Liu, Yuxin Chen, Shangtong Zhang
AI Applications in Finance
⭐ An Augmented Financial Intelligence Multi-Factor Model - University College London
⭐ Hedge Fund Portfolio Construction Using PolyModel Theory and iTransformer - Siqiao Zhao, Zhikang Dong, Zeyu Cao, Raphael Douady
⭐ Deep Learning for Options Trading: An End-To-End Approach - Wee Ling Tan, Stephen Roberts, Stefan Zohren
KAN based Autoencoders for Factor Models - Tianqi Wang, Shubham Singh
NeuralBeta: Estimating Beta Using Deep Learning - Yuxin Liu, Jimin Lin, Achintya Gopal
NeuralFactors: A Novel Factor Learning Approach to Generative Modeling of Equities - Jimin Lin, Guixin Liu
Is the Difference between Deep Hedging and Delta Hedging a Statistical Arbitrage? - Pascal Francois, Geneviève Gauthier, Frédéric Godin, Carlos Octavio Pérez Mendoza
Reinforcement Learning Applied to Dynamic Portfolio Management: A Real Market Data Application - Mattia Mastrogiovanni
A New Equity Investment Strategy with Artificial Intelligence, Multi Factors, and Technical Indicators - Daiya Mita, Akihiko Takahashi
Stock Market Index Enhancement Via Machine Learning - Liangliang Zhang, Li Guo, Zhang Weiping, Tingting Ye, Qing Yang, Ruyan Tian
Infrastructure & Middleware
⭐ Xpikeformer: Hybrid Analog-Digital Hardware Acceleration for Spiking Transformers - Zihang Song, Prabodh Katti, Osvaldo Simeone, Bipin Rajendran
Accelerating Mini-batch HGNN Training by Reducing CUDA Kernels - Meng Wu, Jingkai Qiu, Mingyu Yan, Wenming Li, Yang Zhang, Zhimin Zhang, Xiaochun Ye, Dongrui Fan
Interactive and Automatic Generation of Primitive Custom Circuit Layout Using LLMs - Geunyoung You, Youjin Byun, Sojin Lim, Jaeduk Han
SZKP: A Scalable Accelerator Architecture for Zero-Knowledge Proofs - Alhad Daftardar, Brandon Reagen, Siddharth Garg
🚀 Postscript
Sponsor the Fintech Blueprint and reach over 200,000 professionals.
👉 Reach out here.Read our Disclaimer here — this newsletter does not provide investment advice
For access to all our premium content and archives, consider supporting us with a subscription. In addition to receiving our free newsletters, you will get access to all Long Takes with a deep, comprehensive analysis of Fintech, Web3, and AI topics, and our archive of in-depth write-ups covering the hottest fintech and DeFi companies.