


Hi Fintech Architects,
In this episode, Lex interviews Sam Williams - founder of Arweave. This episode delves into the innovative aspects of Arweave, a protocol designed for permanent data storage and computation within the Web3 ecosystem. The discussion covers a range of topics, from the economic models underpinning Arweave to its potential applications in decentralized finance (DeFi) and beyond.
Notable discussion points:
The Founding of Arweave and its Mission – Sam Williams’ interest in distributed computing and concerns about authoritarianism led him to create Arweave in 2017. Inspired by the Snowden leaks, he saw the need for a blockchain-based permanent storage solution to protect journalism, historical records, and digital assets from censorship.
Decentralized vs. Distributed Storage – Williams explained how Arweave differs from alternatives like IPFS and Filecoin. Unlike traditional storage, which requires ongoing payments, Arweave uses a one-time payment model. This storage endowment leverages declining storage costs to ensure long-term data persistence without relying on centralized infrastructure.
Arweave’s Expansion into Decentralized Compute – Arweave has evolved beyond storage to develop decentralized computing through "Arweave IO." This enables parallelized smart contract execution, making it possible to run AI models, financial automation, and decentralized apps on-chain—aligning with Web3’s shift toward autonomous, intelligent systems.


For those that want to subscribe to the podcast in your app of choice, you can now find us at Apple, Spotify, or on RSS.
Background
Sam Williams is a British technology entrepreneur renowned for founding Arweave, a decentralized data storage protocol leveraging blockchain technology to enable permanent and sustainable data storage through a serverless web. He graduated from the University of Nottingham in 2014 with a First-Class Bachelor of Science with Honors in Computer Science and later pursued a PhD in Computer Science at the University of Kent. Williams began his career as an Assistant Lecturer at the University of Kent from 2014 to 2017 before co-founding Minimum Spanning Technologies, focusing on decentralized technologies.
His interest in blockchain technology, coupled with concerns about global authoritarianism, led him to establish Arweave in 2017, aiming to preserve truthful information and knowledge.
Beyond Arweave, he has served as a Technical Advisor at Minespider, a Voting Member of the LAG Foundation, and a Mentor for Techstars, supporting early-stage businesses and entrepreneurs.
👑Related coverage👑



Topics: Arweave, permanent data storage, Web3, decentralized systems, distributed systems, blockchain, economic models, IPFS, Filecoin, decentralized computing, decentralized finance, compute
Timestamps
1’06: From Distributed Computing to Decentralized Truth Preservation: A Journey into Web3
4’31: Decentralization vs. Distribution: Defining the Future of Web3 Infrastructure
9’41: Building a Decentralized Archive: Arweave’s Journey from Vision to Adoption
16’28: Web3 Storage Economics: Arweave vs. IPFS and the NFT Data Dilemma
22’42: Arweave’s Endowment Model: A Blockchain-Native Approach to Permanent Storage
27’13: Arweave’s Next Chapter: From Permanent Storage to Decentralized Supercomputing
31’36: Decentralized AI and Agent Finance: Expanding Arweave’s Computational Power
36’26: Decentralized AI and Blockchain: Overcoming Computation and Consensus Challenges
41’34: The Future of Decentralized Intelligence: Trustless Finance and Digital Immortality
44’59: The channels used to connect with Sam & learn more about Arweave
Illustrated Transcript
Lex Sokolin:
Hi, everybody, and welcome to today's conversation. I'm absolutely thrilled to have with us Sam Williams, who is the founder of Arweave - one of the groundbreaking protocols in Web3, having started with storage and now focused on computation. Really evolving as a protocol within the context of Web3 can offer the world. And so I'm excited to explore these ideas with Sam. With that, welcome to the conversation.
Sam Williams:
Thanks so much for having me on.
Lex Sokolin:
So, Sam, to get us started, let's talk about your areas of interest and research that led to the eventual founding of Arweave. How did you get into this industry in the first place?
Sam Williams:
Yeah, so I encountered Bitcoin in 2010 or so, but before that I was very interested in BitTorrent, the distributed file sharing system basically.

And the incentives that made it made it work. And somewhere after my undergraduate degree, I decided to go into a PhD position. I was also applying for postdocs at the end of it, but I ended up finding out. And in that intervening period when I was in the PhD program, I was building essentially a distributed operating system. The idea was, can we create a compute platform where the execution of code would continue if parts of the individual machine that it was running on failed. And this was basically building on a set of work that was called, I guess collectively, multi kernels, which was pretty interesting stuff, but it wasn't yet distributed compute on its own. At this point I don't think is a well changing idea. Decentralized compute is extremely interesting, but distributed compute. So that is yeah, distributing a task on an operating system between many different cores or machines in the local network in a permissioned environment. Just. Yes. It's not going to change the world at this point.

And nearing the end of that program, I was supposed to be writing up the thesis, and I got looking at the world and how things were moving, and I saw that this was really after the Snowden leaks in, I think it was 2014 or so. That really changed my perspective. And I started to see that essentially the, the stagnancy of at least the Western world that had existed for my whole life until that point, like I was born in 1992, became sort of vaguely aware that things were happening outside my tiny area, probably just around 9/11, I guess. Yeah, a little bit later, before I had any like real political consciousness, you could say. But during that period, things were relatively stable. And, and I saw it starting in around 2015 or so that, that there were destabilizing forces in the West, you could say. And I was very against the idea of living in an authoritarian society. I'd read enough history to know that that sounds like a horrendous, yeah, horrendous thing.
And, I thought, well, it'd be good if everyone else around me also didn't have to live through that. And I started reading some books that became very, influential in my thinking, I guess, about basically how those Authoritarian societies operated and developed, and one of the core components was at some point, an authoritarian regime has to gain control of the perception of truth amongst its populace. And this is, you know, fundamental, because if you don't do that, then people will notice what is happening to them and one way or another demand change.
Lex Sokolin:
It's quite on point for the current moment. I wonder if those books were recommended to you by a social media algorithm that was built around you to provide you things that you would find intellectually compelling?
Sam Williams:
Yeah, I guess I must have first heard of them through social media, but one in particular was so obscure that it was out of print at the time that I. The author won a Nobel Prize for writing it, Alexander Solzhenitsyn.

And yet at that time, you couldn't buy a physical copy because no one was publishing it. So, it was it was fairly off the beaten path, but I'm sure I first encountered it as a result of social media, which was kind of the direction we were moving and wanted to create, and this is what eventually ended up becoming. With a ledger of speech that was open for everyone to access, everyone to write to, and that would replicate that speech over time without any centralized authority or controller being able to get in the way of that process. And, you know, I knew about bitcoin, of course, and Ethereum. Yeah. From the from the early days. And I saw okay, well what do blockchains do. They replicate information around the world without a single centralized point of failure. That sounds like exactly the solution to the problem I'm trying to solve. There was born the idea of basically, which is permanent data storage on chain at any scale, distributed around the world.
Lex Sokolin:
I'm excited to go into the details in a moment, but before I wanted to tease out the definitions of the word distributed and decentralized.
And of course, both of those words have meaning within context, you know, and then also they can be really technical. If you were to try and boil things down to their core, what's the distinction between those words? Like when are they used? Because distributing a computation task versus having a decentralized network is quite different. There might be listeners who've been trapped in enterprise blockchain and think that distributed ledger technology is the same thing as, you know, EVM. So, can you give us some demarcations of what those words mean?
Sam Williams:
Well, I'm about to irritate approximately 50%, I would say, of the technical listeners. So sorry for that. But at the fundamental level, and on the technical side, yeah, the definition of decentralized is much easier to create or synthesize. Synthesised then, then distributed. Decentralised simply means that there are no centralized points of failure or central points of failure, so any number of nodes in the system can go offline at a certain point in time, and the system continues to operate.

There's no central node to which all of the other nodes ultimately report distributed is a little bit harder to define. I guess it is basic level. It's a computation system that involves multiple parties, but that's so general is not to be useful. I think that in the social context, the way people normally use it, and I think has perhaps the most. Yeah, the most we say helpful definition in practice is that distributed typically speaks about a permissioned setting or a system that is non consensus based. So okay, that makes the other side of the decentralized definition, which in the social setting also tends to describe systems that have some sort of consensus system, upon which there is no requirement for that central authority, whereas in distributed systems. So BitTorrent would be a distributed system, for example. All of the early versions of academia from 1999 through LimeWire, Kazaa, Napster, they all used some variant of that system. And interestingly, actually Spotify used BitTorrent underneath for a while.

Lex Sokolin:
Yeah, I mean, Spotify is just Napster with a subscription, right?
Sam Williams:
Exactly. It's actually like a a paid torrent tracker, essentially. Or at least it was. I don't know if they still use BitTorrent, but I did think that was interesting at the time. But yeah. So distributed systems can also often refer to the permission settings. So, the distributed operating system I was working on in my PhD as that was a distributed system. Yes. But more importantly perhaps for the conversation we are having. It was based on the fundamental assumption that the other nodes in the system are going to be added by a trusted party, and so they could be trusted to some extent. The system has to be tolerant of failure. So, when that node starts to do something wrong, but it's not expected that that node will act deliberately, maliciously, whereas in a decentralized setting, that's actually typically our base case is for what's the worst possible thing that an actor in the system could do. And let's model based on that.
Lex Sokolin:
Switching back to Arweave and its founding, can you talk about the initial product proposition and what the world looked like when you were building that product? And then maybe we paint a picture to how it was used and what kind of adoption it achieved.
Sam Williams:
The initial product vision is essentially what Arweave is today, which is just a permanent data storage ledger, our core sort of objective. You know, judging. Yeah. The criteria by which we would judge if we were successful had we created an archive that is decentralized and permissionless, but also can store large amounts. And then with 2.0, which came a couple of years later, arbitrary amounts really like any quantity of data, which was typically records of history. So, we just wanted to create an archive of newspaper articles to begin with so that journalists could speak and be sure that that information was not going to be censored by any party that could get in the way. And the first reception to the idea, it was we were very lucky that we started with in the summer, where it became public, at least in the summer of 2017, which, yeah, I think you have quite a background in crypto. So, I'm sure you're aware of how the market sentiment was at that time we had atrocious marketing.

We had this terrible website, which was good for a technical person that cared about, you know, the objectives we were talking about and for whatever reason, felt the need to spend 15 minutes reading through text. It was like an okay description of what we were doing. But we were very lucky in some sense, that the market was so exuberant at the time because people backed us to build this thing about $400,000 worth at the time, which was enough to build out the V1 of Arweave. And then we launched it, and no one used it for I remember vividly a day about five months in to the mainnet launch, not a single transaction was sent by any user anywhere in the world, which is quite a feat in itself to some extent.
Lex Sokolin:
Yeah, I mean, that's not good. Yeah.
Sam Williams:
But then I think that people slowly started to understand what it was for, and we are also the only real pivot, if you will, for Arweave in. This didn't happen at a technical level.

It happened. Social level was observing that, okay, cool, we can store newspaper articles, but actually what are they represented as the web pages? So actually, what we built is a decentralized web. That's kind of interesting. And because it was structured like an archive, everything was indexed and so you could query it. And so, to your point about social media earlier, you could do things like build decentralized social media applications on top of it, which, yeah, which had no single centralized point of failure and were transparent in the way that they operated. And then we started to talk to people about this. And yeah, I mean, long story short, where we're standing today, it’ll be passed 35 million pieces of data to the network each day and just passed 10 billion in total. So, from that zero per day at the beginning things have grown really, really exponentially since then, which is very exciting. And along the way, one of the first points of usage of the network, which sticks out in my mind, was when people used it in Hong Kong to store basically archives of newspapers that were being forced to shut down while the national security law was being passed or shortly thereafter.


And this was something that happened if we'd done things to sort of push awareness about it along the way. But this has essentially happened organically in the end, and we learnt about it when everyone else did, when there was a newspaper article, or rather a Reuters article, I think it was, and it woke up one morning and I was like, oh wow, you've actually using the technology for its intended purpose. And then came a sort of classic bitter irony of life, I guess, which was the next thing that people used it for. And they did so on a mass scale where storing pictures of gorillas. Because if you have an NFT and you want to trade on the value of that asset than not having that NFT disappear and subsequently using reverse storage endowment, which is engineered for data permanence, turned out to be a perfect fit. And that crowd of people were also very aware of it. And so that led to a huge growth in activity on the network. But since then, many people in crypto, particularly the builders, have become aware of the system and they started using it for really endless different use cases.
This is really exciting to see everything from running Web3 social media. So, things like Lens store all of their records on Arweave in the background to storing chain records that a system called Chives that archives blocks from other blockchains in a place where the data is actually replicated and paid for over time, such as blocks can never disappear and a ton of other things. And so yeah, it's really grown. Well, we're happy about it very well. Since that initial slow start, I would say.


Lex Sokolin:
A couple of things come to mind. Some of them are maybe naive questions and maybe a little bit irritating to you, but I'm going to go there anyway. A lot of the Web3 blockchain world is quite special, because it's a place where the CTOs can escape all the MBAs. You can build the technology without having to have a co-founder that's trying to be CEO and making you do things. As a result, you do get outcomes, like you said, where, you know, there's a lot of protocols that are highly technical, that aren't optimized for distribution necessarily but are solving real problems.
And it's I think it's the lucky ones that actually find a product market fit like you have and kind of grab on to it. The boom that we, we saw in NFTs and having to store underlying data for NFTs created huge demand around 2020, 2021. And of course, that that demand has transformed, and we can talk about that as well. But in that moment when the NFT boom happened, and it became clear that the decentralized world needed someplace outside the computational blockchain to actually put the stuff. There are two options. One is Arweave, and the other one is Filecoin and IPFs. And the models seemed to be quite different. And this is probably where my understanding is naive, where with something like IPFs, you are renting storage that's being provided by a network of people that are contributing hardware. And with Arweave, the storage is permanent. You pay for it once and you have it forever. Is that right? And then number two, how do the economics of that trade off make sense? In one case where you have a renting network and the other where you have a permanent network?
Sam Williams:
That was correct. Apart from the word forever, I wouldn't use that personally, but I can tell you how it works. And then elegantly, because it's a protocol, you can validate it, and you can see for yourself how much you trust it. And I think that's the only way a service like this could actually possibly ever be rendered. So essentially what it does is it creates a storage endowment every time you upload a piece of data to Arweave you pay for 200 year’s worth of that storage at current costs, and then as the cost of storage declines over time, that’s essentially runway, if you will, that event horizon expands out. So, if the cost of storage never declined again and the token price to remained stable, you would just get 200 years of storage, 20 replications around the world in a decentralized network. But if the cost of storage declined at a rate of 0.5%, then you would actually end up with a constant horizon on your storage endowment contribution, which is a very interesting well, it's an interesting financial mechanism, but it's also just an interesting observation about the acquisition of services over time.


And of course, in the case of Arweave, where we have an unstable token price and so we add in a massive buffer for potential volatility that will emerge inevitably in the price of the token and also the storage markets. So, when you upload to Arweave for a 200-year horizon, that implies a 0.5%. We call it a Kryder plus rate. It's like the yeah, he was one of the early founders of the hard drive industry, but he basically made this observation about the declining cost of storage over time. So, if the Kryder rate was to be 0.5%, then you would create a consistent storage endowment runtime at 0.5% in the real world. But if you actually look at the history of data encoding costs over time, and this is a pretty interesting study that we ran at the beginning to see if this was viable. We saw that not just the beginning of modern digital storage mechanisms, but actually all the way back through history, like on the multi thousands of year time horizon, the cost of encoding data has been dropping at a really staggering rate at a very, very consistent form.

Yeah, over a very, very long period of time since the digital computer revolution. It has been declining at a rate of about 38.5% approximately per year on average. And before that, it's a little bit harder to tell, but it's at least into the 10% approximately rate. And of course, you know, you go so far back you can't even you can't really measure it in dollars, certainly. But money even you look at like key falls and okay, how much did it cost? How much time had to go into encoding a single character in a way that data would be replicated for a certain length of time? Long story short, you look at this, it's like humans. For whatever reason. We just love to make the encoding of data cheaper and how Arweave essentially makes use of that and turns it into an endowment structure. You essentially generate storage, purchasing power, interest on your principal, and then you use that. And then over time, your storage horizon expands out. So, this was our model.
We frankly, haven't seen another model that's remotely viable even since we since we came up with this one. And ironically, it was sort of adopted by the Filecoin crowd who attempted to make what I would call bad imitations, unfortunately, since then. But to your point about IPFS, I think that's actually a great example of a distributed network rather than a decentralized network. So, in IPFS you don't rent, at least at the base layer that your, your data is replicated inside the system. Instead, you just run a node, and you pin a file. And as long as someone is pinning a file, there's some expectation of even that can be, you know, questionable sometimes that that data will be available via routine. So can you find the data in the network, the bit that people miss about IPFS is, ironically, exactly the part that is in the headline in the name itself. It's a file system. It's not a hard drive, whereas Arweave is a hard drive. It has file systems built on top of it, but it's there to store your data over time.

And then, yeah, in the NFT boom. I'm so glad you asked about this, actually, because it's a pretty interesting situation playing out that no one seems to be paying attention to. Yeah, you're absolutely right. The big places to store your NFT data were Arweave and IPFS, it wasn't Filecoin because that launched later. And people even now seem to have a problem actually uploading data to it and having that data be available. But when people put the data onto IPFS, there was this expectation that someone would pin it. And Protocol Labs, the creators of IPFS, they built a service called NFT.storage, and they promised people a permanent data storage forever. They used the word forever no less for free, arbitrary quantities, which was obviously not going to work. You know, one of the learnings I've had, I guess, while building Arweave, is that people don't necessarily pay attention to the details. They can be quite surprisingly misled without, you know, without looking into things. And so people believed that some people, maybe 50% approximately these claims from the Protocol Labs crowd as of today.
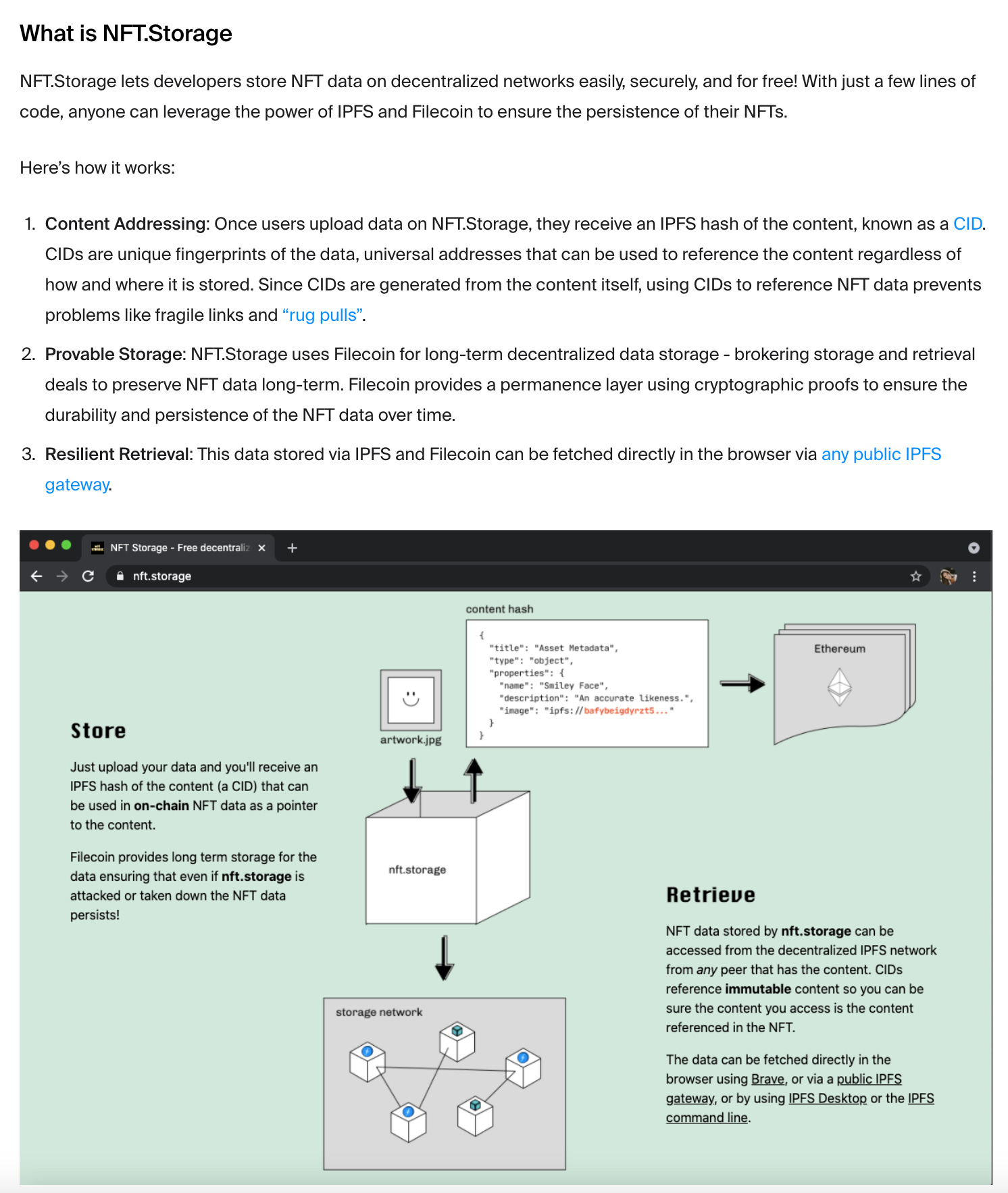
Yeah, NFT.storage is seeming like it will shut down and all that data will be lost. And now they're sort of trying to crowdfund for it to keep the alive and keep that data around. Whereas obviously if you put that data in Arweave all that data is still there. It's the endowment lifetime, I think has even grown during that period of time, and it's replicated in this point. I'd have to check the numbers, but it's into the hundreds of places around the world on average.
Lex Sokolin:
That's really interesting. I think it's a little bit heady. So, the endowment model is you've got some assets and the assets throw off interest and therefore that interest can pay for ongoing cost. And then because the cost collapses, it becomes cheaper and cheaper to run. Is that the right way to think about it?
Sam Williams:
Not even, it's not that you have some assets that are producing intrinsic yield themselves. Is that actually the price of acquisition of the thing that you're trying to get good declines naturally. And so, you don't need to put the this is one of the ways that in the Filecoin ecosystem, while trying to mimic Arweave, I think they either weren't thinking long term or they or they didn't think this through and notice it.
Yeah. If you expose that capital to risk, well, actually your lifetime of the endowment drops massively. And so, with that, all we do is just keep the tokens. But the cost of the good in the economy that is storage purchasing. Yeah. Storage over time tends to decline. And as long as it declines over a rate higher than 0.5% on average given average token price or unchanging token prices, then the amount of time you have in your runtime, basically of your income. Initial contribution stays stable. So, you have the same amount of capital, but the cost of the good is declining.
Lex Sokolin:
It's very novel because often the crypto world tries to win on cost comparison relative to web2 provision. You know? So, it's like you can get this thing there for a dollar, but over here it's $0.99. And so come over. And in many ways people were booting up these decentralized physical infrastructure networks and continue to do so with the cost value proposition, which is a very different value proposition than what I think is at the core of Arweave on the hardware side, like where does the hardware come from and what are the tokenomics for people who participate?
Sam Williams:
Yeah. So mine is compete with one another like they do in Bitcoin. The interesting thing is that the price that the network pays to buy storage relative to average cloud prices is very, very low because we have that effect of, yeah, a decentralized physical infrastructure network where miners compete against one another to provide the service in a minimal, viable way, as low cost as possible. So that works very much the same way as Bitcoin and other deep end networks. But absolutely, to your point, the model is very different because we wanted to offer people a service that they simply couldn't buy from a centralized party. And when I spoke at the beginning of this segment about the endowment, about, yeah, the whole idea is not to for you to have to trust us, you can just go read the paper yourself and go read the code and validate what it does. That's not something that a centralized company could ever offer to you. And no, no code really. They offer you long term storage on that sort of time span of decades in a way that a protocol actually can.

So, I think that our web is like the perfect confluence of, yeah, it couldn't have been done with any other technology before it, you would always have to trust some sort of centralized management structure. Whether that be a foundation or a company wouldn't really matter, because you're putting your trust in other humans to execute it. Whereas what I was trying to do is absolutely minimize risk, put that risk in a model that people can very clearly see and validate for themselves, and then purchase the service and know that it's going to execute in a certain way. And no human on earth or a group of humans can change it against them. It's a very different way of thinking about things. We see it as blockchain native, basically, rather than trying to skeuomorphic bring services from the web2 world. Layer them on top of a blockchain somehow. It's actually the web2 world. You know, there's a reason it's so big. Like it works for many different use cases, whereas there are some things it just can't do. And so Arweave leans into that.
Lex Sokolin:
We've covered that initial value proposition. And you know, recently I've seen announcements from Arweave about compute and evolving the protocol forward. And I think in 2024, the trends that are here are quite different. You know, the NFT market is, loosely speaking, depressed, but more directly pretty dead. Yeah, pretty dead. And instead, we have a lot of conversation about these deeper networks, you know, attaching different machines, recreating telecoms on chain. And then of course, we've had the crypto AI boom, especially in March of 2024, as different protocols have come to market focused on GPU, focused on inference networks and so on. So, the type of computation and the purpose of it is different from storing gorillas on chain. Can you talk about the use cases you're seeing now and then where the technology is going.

Sam Williams:
To the point of NFTs, I think that NFTs, as that currently formulated, are basically dead, but the underlying value proposition of well or observation, you could say, which is the digital content does evidently have value.
It's just a question of how to unlock that. I do believe that is true and that it is. It's going to play out. Yeah, it'll play out over time. It's not cool today. But to be honest, like when we started Arweave storage was not particularly cool and certainly not permanent storage. I mean, there was nothing else that it was even in that area took quite a while for it to appear. So, we don't mind being uncool as long as we believe that the proposition underneath is actually logical. Yeah, we're certainly not evolving the protocol of Arweave either. That's something that's interesting. We are instead building on top of it, a compute layer that we call the actor-oriented computer. It's not built into the core protocol because the protocol is, you know, as I just described before, an immutable piece of public infrastructure that all people should be able to rely upon without having to trust that we're going to come in and, you know, modify it all the time.
So instead, we're focused on, well, how can we put it to good use? How can we basically grow the use cases of the network. Yeah. One area that we see a lot of excitement and growth at the moment is Arweave as a permanent storage layer for interactions on other blockchains. I mentioned before that there's a system called archive, which basically archives blockchains to Arweave. And when you do that, you have essentially created a trustless, decentralized ledger of interactions. And we were thinking about this during the bear market, and we had a sort of idea for a design of how you could build a computation system directly built on top of that, which eventually became, oh, we used that time to, yeah, build while everyone was depressed. What came out of it was basically a decentralized supercomputer. The thing that we think is it’s interesting, this time last year, it was a very uncool idea in global shared state, which is the Ethereum model, or at least a model that was pioneered by Ethereum, Followed by Solana and pretty much every other blockchain.
Although Ethereum is now moving in the direction of rollups and potentially something closer to the original vision of shards which don't have global shared state and are actually relatively close, but not relatively close, but certainly similar to what we built with AO, which was a hyper parallel computer. Basically, the idea of, well, instead of having rollups per se or a global shared state. Wwhere everyone comes to consensus about the state of every interaction in the blockchain, every time an interaction is made, what we could do is we could say, okay, there's as many blockchains as there are people that want to interact in the system. So, each application can be a process, and that application can actually be made up of any number of processes underneath it. Each of those processes is essentially a blockchain. And then we share the infrastructure. So, the scheduling units we call them which do I guess if you're thinking in rollup terms they that kind of like sequences and the compute units, which essentially evaluate the actual state of a smart contract.

Yeah, we share that infrastructure around between all of the different processes and allow them to call upon it, you know, arbitrarily as the user requires, and you glue it all together and you end up with a globally decentralized supercomputer, it has no limit on the number of processes that can run in parallel inside it. And they can have a whole CPU thread basically. So, the maximum throughput that you could get on a single normal computer per process. Yeah, we're building on top of Arweave of course, which now in production is running at 350 transactions per second on average over the last year. Sustained. So, it's really like an extremely high throughput system. And we built it. So, we know how much it will scale in the future. And we just saw that okay. Well, making it so that people can build their compute applications on top of it would open up the use cases quickly. And it certainly has done on its own. Just the testnet has now pushed 700 million transactions to orbit, which is really pretty staggering. We have a very long time to get to that level.

Lex Sokolin:
What are those transactions? What kind of transactions are they?
Sam Williams:
Many different things. Some of them are the types of things you'd expect in a typical DeFi ecosystem, like people swapping tokens, that type of thing. But one of the really exciting things about AO is because it decouples the storage layer from the compute layer. So that is consensus and availability of the data itself, the transactions that people are sending and the programs that are executing from the execution of those programs. You can basically have arbitrary amounts of computation happen inside those smart contracts, and then only the people that are actually needed in order to guarantee the security of those processes have to actually execute it. And long story short, what this means is that you can do large scale like in a normal personal computing, except in a decentralized environment. So many of those transactions each day are people uploading or they are uploading, but from their point of view, they're interacting with an autonomous world on top of the system that we call reality protocol.

So, they're walking around every time their character takes a step. That's an on-chain interaction, and that's it. Like it's somewhere between a 10th to a yeah, somewhere between $10 approximately and $1 per million interactions of that type. And if you don't need to buy large scale security for it, it remains that cheap at scale. So, you can use it for many things that really you just couldn't use a traditional decentralized compute network for.
Lex Sokolin:
So, there is an application that is building out a digital twin of the world that is using AO, which is then storing the data on Arweavee.
Sam Williams:
Yeah, exactly. So, it's a sort of layers of a cake. At the top. You have the, for lack of a better word, metaverse that people are interacting with. And beneath that you have the compute layer, which is resolving those interactions from users to something that looks and feels like a mutable, interactive application. And then below that, you have Arweave, essentially the ledger that is replicating that information around the world. But then other people are using the system for AI use cases.


So, some yes, you can run just large scale LLMs, the normal type, like pretty much every basic model that you can get your hands on in the open source community, on chain, in smart contracts, and then having multiple compute units attest to the correctness of that execution, which we make deterministic through a system called WebAssembly. But others are also using it to essentially execute in the financial apparatus of AO. And this is really exciting. It's, for lack of a better word, agent finance. So, the idea that you can create an intelligence that executes for you in the market on your behalf while you're offline or someone else can build it, perhaps, and you don't need to trust that person to build it, built it in order for it to execute for you. And so, this is very, very different to the traditional DeFi infrastructure, which was really just focused on settlement. Now you can have intelligent money management basically. Yeah. Financial strategy execution without trusting any single centralized third party.
Lex Sokolin:
My mental model for how today's version of DeFi, and sort of the very narrow bandwidth blockchains that have the large footprints can interact with AI is that in today's world, you can have off chain models being run locally or in a distributed way, however, but, you know, not connected to a blockchain.
And then they create some sort of output, some inference output. And, you know, there is a verification technology, whether it's zero knowledge proofs or T that verifies that the particular model you expect it to run did run. And then you can bring that inference on chain, kind of like an oracle. And then people that are in the blockchain world in the sort of like very narrow bandwidth world, are then able to rely on it. At some point, it had gotten translated into intents that that have been generated from users saying, I want this particular trade, or I want this particular money movement and so on. That's the framework for where most of Web3 is going with the current capability. I mean, you're trying to shove a supercomputer into a Nintendo and then saying, why doesn't this work? But then the other folks who are kind of working on this problem are near and definitively. I've heard Dom from Dfinity claim that you can load in maybe like a 60 billion parameter model into Dfinity, infinity and then that can actually execute inside of it, but pretty much takes up all the bandwidth that there is. Can you explain where what you've described sits in between those?
Sam Williams:
I think you can split the different approaches into essentially two buckets. One is the specific proof system bucket. So that's something like a ZK proof or an optimistic execution of an LLM on chain or rather off chain and then producing some sort of proof or responding to challenges on chain. Those tend to be pretty frankly, weak that all of them. I think if you speak to the engineers, which we often do, because as you might be able to tell, we spent a lot of our time in the engineering world of crypto. There's a bunch of different ways these things are. They deviate from the typical levels of security that we would expect from a blockchain when you execute them. And the problem, of course, with that is that when you take these outputs from an LLM, and you execute a financial transaction based on them. You have to have them really with extremely high levels of certainty, of correctness. And then the other bucket, the closest thing to you.
Oh, I think at this point is ICP. Yeah. That Dfinity are creating. But they definitely don't run 60 billion parameter models on chain. I think they have a 1 billion parameter models or something sub GPT two level.

Lex Sokolin:
I think any mistake in the framing is 100% mine. I'll take your word for it.
Sam Williams:
You know how it is in crypto. The marketing is very exciting, and the reality is often not quite that much. But basically, ICP is in the same sort of direction, but they still have that architecture where they have tied together computation and consensus about inputs. And this is, we think, there’s a fundamental error because it leads to the situation you outlined, which is like, well, when one person wants to execute on like that sub GPT two level intelligence LLM. No one else can do anything with that subnet and with AOP. Instead, take an approach this kind of closer, I guess from the basic theory point of view to Ethereum L2, where we say, okay, well, only the actors that care about the execution should actually have to do it.

But there's different buckets that ICP and AO are in, is that we just focus on solving the general-purpose computation problem. And so, we have WebAssembly 64, which allows us to have pretty much arbitrary sized LLMs inside the system. It's like smart contracts with 16GB of Ram. We've done in practice at the protocol level, at least you could go far, far higher than that. Yeah. And then you solve the question of, well, can you just compute anything? And subsequently you get with that for free AI workloads. So, we're we're focused really on solving the problem of building a decentralized supercomputer. And then second to that is the AI specific use cases, although we're using it as sort of a benchmark because it's by far the most compute heavy execution you can really execute today. So, if you can support that, you can support pretty much anything at scale. And so yeah, we think it's pretty exciting. I would encourage people, if there are developers listening to go actually check it out and try it for themselves.
It's pretty cool talking to a fully decentralized autonomous intelligence. It's a very different proposition than the OP/ML type operations that you see everywhere in crypto typically. And they have this problem specific proof system direction that, well, you change the model a bit or you change the operating system environment. So, the operating environment around the model somewhat. And now your proof system doesn't work. And yeah, I mean I could go for hours about why that direction is not wise.
Lex Sokolin:
Yeah. Yeah. I mean it sounds like you're quite far ahead to me. It's really encouraging to see this is possible. And of course, all this tech is still experimental and there's a lot more to do. But the idea that we have networks that can execute software with much larger throughput, you know, and not just simple transactions at larger scale, but be able to do something like load in a machine intelligence model and run. It is really interesting and is much more powerful also, I think, than the types of inference networks that we've been seeing that are playing around with Tokenomics, but not actually focusing on intelligence.
If your bet is right and we see more effort towards things like world computers, global scale decentralized computers that incorporate intelligence in them, and then where intelligence is circumscribed in some packaging, you know, whether it's Dow or corporate or some other packaging that allows it to be useful and economically productive. If that's really possible. It has to draw a huge gold rush because of how I think profound that is for humanity. What do you think the world looks like? You know, if it's real and true, right. And in five years or ten years where you've got global scale networks and I mean, you're telling me that it's there today, you've got global scale networks that are doing this. What implications does that hold for the for the rest of it?
Sam Williams:
Well, I would argue don't trust, verify, go run it and play with it. Yeah. So, you can certainly do this today. I think the obvious use for the system first is trustless financial strategy execution, which doesn't necessarily seem to be where all of the focus is in the crypto, hype space.
But it does strike me as the most obvious practical implication. Yeah. Something you could do today that you couldn't do a year ago, for example, that's basically, you know, just like we had DeFi summer, any random developer can now, like in a basement somewhere. Who knows? No one knows who they are. They're just like an add on Twitter. They build a cool strategy, they launch it. Other people can deposit money into it. They can audit what it's doing without having to trust that developer. And then they can take their capital out when they want to. And if you look at the way that the financial system works, something like 70, I want to say 78 or 72, I forget percent of the transactions that happen on Nasdaq happen as a result of an agent of some form, obviously off chain agent, where someone has trusted a computer program to execute something for them. And we now see that you can basically have the doing air quotes here DeFi effect at that layer of the stack as well.

You can make all of that execution trustless. And so you can open up innovation, you know, now suddenly, instead of everyone having to trust the financial institution that they're working with, you can just audit the code together and say, okay, yeah, you know, if you want a portfolio agent, for example, or something that buys and sells based on sentiment on Twitter, this is a very reasonable way of doing it. And you can order that code yourself. You don't have to trust anyone, it just executes on your behalf. So, my sense is that that would be the first major breakthrough in end user facing products or applications of this technology. And then further down the stack, I mean, there's all sorts of implications of this. Just want to throw it out there. And sure, we don't have time to discuss it in enough depth to really get to a justice, but if you can have an autonomous LLM that is trained on a certain set of data, and there's nothing that stops you from training it on, you know, your outfits, everything you've ever put into a computer or that of a and a famous person like Einstein, for example, and then making a sort of, like I said, not enough time to discuss this in appropriate depth, but at minimum, what you've created is a sort of talking almanac, a talking memoir for every person that is available that kind of passes there the legacy or essence of who they were, what they thought about forward.
And you saw it on Arweave, and it's backed by the storage endowment where there's no trust in the centralized party. It's just transparent what it will do over time. Yeah, it will replicate it for extremely long periods. And so that we think is extremely interesting as well. But I would say it'll take some more time for people to understand this properly and to, to start. Well, first building it, you see already the first, you know, experiments in the Arweave ecosystem of people trying this out. But then to really grapple with what it means, I think will take a decent period of time.
Lex Sokolin:
This has been an absolutely fascinating discussion. I definitely encourage our listeners to go learn more about Arweave and go and check it out. Sam, where should they go to go deeper and also to learn more about you?
Sam Williams:
Yeah, for sure. If you want to learn more about, just go to ao.arweave.dev or actually any Arweave gateway will work, arweave.org.
We have a website of course, but also the community does as well. There's this thing called arweave.hub. So actually, if you just Google Arweave and you look through the links, you'll find a bunch of stuff about the community. It's pretty autonomous at this point. So, I don't want to favor one source over any other. But also, a bunch of us are still unfortunately on X. And so if you just search Arweave there, you'll find us pretty quickly. I'd say.
Lex Sokolin:
Fantastic. Thank you so much for joining me today.
Sam Williams:
Thanks so much for having me on.
Postscript
Sponsor the Fintech Blueprint and reach over 200,000 professionals.
👉 Reach out here.Read our Disclaimer here — this newsletter does not provide investment advice
For access to all our premium content and archives, consider supporting us with a subscription.









Share this post