

Hi Fintech Architects,
Lex interviews Michael Heinrich, co-founder and CEO of 0G (Zero Gravity) Labs, a decentralized AI network that has recently raised $290MM at around a $2B valuation. In this episode, Lex and Michael explore the concept of decentralized artificial intelligence (AI) and how it differs from centralized, closed-source AI models provided by big tech companies. Michael kicks off with his background in tech and finance, and how he became interested in decentralized AI as a solution to the issues with closed AI systems.
Notable discussion points:
Decentralized AI provides transparency and verifiability around the data, training, and model alignment used, unlike closed AI systems.
Blockchain-based systems can help enforce a "code of conduct" for AI models and ensure fair rewards distribution for data contributors.
0G Labs is building a decentralized AI operating system focused on key components like decentralized storage, data availability, and a serving layer for AI inference.
The company is working with various providers of AI verification mechanisms (zKML, OPML, TEML, etc.) to integrate with their decentralized AI platform.
The ultimate goal is to provide a seamless user experience for building and deploying decentralized AI applications, similar to how centralized tech platforms operate today.


For those that want to subscribe to the podcast in your app of choice, you can now find us at Apple, Spotify, or on RSS.
Background
Michael Heinrich is an experienced leader and serial entrepreneur driving innovation at the intersection of decentralized AI and blockchain as CEO and Co-Founder of 0G Labs. Previously, he founded garten, a Y-Combinator backed corporate wellbeing leader, scaling it to $200M+ in revenue and $125M+ in funding.
Michael’s career spans roles at Bridgewater Associates, Bain & Company, SAP, and Microsoft, as well as angel investments in multiple unicorn startups. A Stanford lecturer and mentor, his class Hacking Consciousness earned Apple’s Best of recognition.
A UC Berkeley summa cum laude graduate with degrees from Stanford and Harvard, Michael is a lifelong advocate for wellness, meditation, and Shaolin Kung Fu.
👑Related coverage👑



Topics: 0G, 0G Labs, Zero Gravity Labs, Bridgewater Associates, ORA, Story Protocol, AI, Artificial Intelligence, Decentralized AI, Tokenized AI, Web3, Blockchain, zkML, TeeML, OPML, SPML
Timestamps
1’10: Decentralized AI: From Early Tech Fascination to Innovating the Future
4’08: From Finance to Founding: A Journey of Passion, Growth, and Resilience
9’07: Web3 Meets AI: Building a Human-Centric Future Through Blockchain Innovation
13’45: Decentralized AI Explained: Trustless Systems vs. Closed AI Paradigms
17’21: Decentralized AI Solutions: Addressing Bias, Censorship, and Fair Rewards
23’30: Decentralized AI Framework: Building Open, Trustless Systems for Developers
27’28: Data Availability in Decentralized AI: Supercharging Blockchain for High-Performance Applications
31’24: Integrating Decentralized AI: From User Queries to Scalable Inference Frameworks
34’38: Tokenized AI Ecosystems: Economic Flows and Emerging Inference Networks
40’04: Ensuring Trust in AI Outputs: Bridging Verification Mechanisms with Decentralized Systems
42’13: Decentralized AI's Future: Breakout Use Cases and the Path to Mainstream Adoption
44’40: The channels used to connect with Michael & learn more about 0G
Illustrated Transcript
Lex Sokolin:
Hi everybody, and welcome to today's conversation. I'm really excited to have with us Michael Heinrich, who is co-founder and CEO of Zero Gravity Labs. Zero Gravity Labs is one of the most interesting companies out there focusing on decentralized artificial intelligence and lots of other adjacent topics. So, we're going to explore what that is as well as how Michael got to this position and figuring this out. So, with that, Michael, welcome to the conversation.
Michael Heinrich:
Super excited to be here. Thanks for having me, Lex.
Lex Sokolin:
My pleasure. Let's start with your career arc. How did you end up in this science fiction magic world of decentralized artificial intelligence where it was there? Were there things that you've done before?
Michael Heinrich:
It's interesting. I think I started on deep tech and was really fascinated with it and then did all this stuff and ended back into a deep tech industry. So, the very first time I got super excited about it is, I think it really started with my dad's influence. He was running a software company when I was younger, and I would just show up to his office. I was maybe eight years old, and I was playing some DOS-based games at that point, like Soko-Ban and so on. And that was really my first foray into like, oh, this is cool. Technology can give me entertainment.
")
And then when I was 13, we moved to Silicon Valley from Berlin, Germany, where I'm originally from. My dad worked for SAP, and so got a role at SAP Labs in Silicon Valley, and I would resume the same pattern. I was a little bit bored in high school and I was like, okay, what do I do with my free time? So, I would just show up to his office and there was a superfast internet connection, friendly people, and I would also sometimes just go around and help people defragment their hard drives. That was a thing before SSDs.

And people were like, "Oh, there's this nice kid that's going around and helping me out," and at one point of the managers discovered me and he said, "Hey, why don't you actually do something else that's useful?" And I was like, "Oh, what should I do?" He was like, "Well, why don't learn how to program and help us build some of these systems?" Like, "Oh, that sounds cool, but I have no idea how to program." He's like, "Don't worry about it. I'll send you to a bootcamp," and so two weeks later I was in a Visual Basic bootcamp at that point, and I came back and essentially started coding some of the first Web2 HR self-service applications.
And so I was too young to actually get paid so what they basically did was like, "Hey, we'll give you a bunch of free hardware and you help us out here and there," and I was in total heaven. I was getting the latest ThinkPads and I was like, "Oh, this is so cool. I can play around with technology." So that's really how I got into it. It was more by happenstance. I just happened to be at the right place at the right time.
Lex Sokolin:
So how does this person that likes to defragment hard drives for fun, you did make a stop at, it looks like at JPMorgan, Bain, Bridgewater, the ever-present finance galaxy of positions. What was the path into there and how did you rebound back into tech?
Michael Heinrich:
So, I started getting more interested in the business side. I started doing more technical product management at SAP first and at Microsoft foreign internship. And I got really fascinated with the business side. I was like, oh, there's this whole unexplored area that I know nothing about. And then in college when I was going to UC Berkeley, I didn't quite have as much fun in the computer science courses because they were very much designed to weed out people and just tons of homework and tons of reading and so basically one class was worth three classes of effort. And so, I basically said, "Well, there's this other stuff, business stuff that seems like so much fun and much easier, so why don't I explore that?"

And so that's how I then started getting into it. I was part of a business fraternity called Beta Alpha Psi, and then from there basically set the goal, okay, I really want to explore management consulting because they deal with executives, and I want to learn all of the strategic aspects. And so first went through an investment banking internship at JPMorgan, and then after college got into Bain & Company and worked there for a couple years, and then from there moved into Bridgewater Associates.

On the TradFi side, I was on the portfolio construction side and was just really fascinated with finance. So, before I finished Berkeley, I also did research at the Harvard Business School on global capital markets and discovered a bit of a passion for finance as well. And so that's why then after Bain I basically said, okay, I need to go back into finance because it was a lot of fun when I was doing research on it.
And so that was the arc. It was really much interest driven and passion driven. And then after some time at Bridgewater I did realize that I wasn't feeling fulfilled, and one of the reasons that came up that I later discovered after doing a lot of inner work is that I was just collecting a lot of logos and top schooling in order to appeal to my dad to basically make sure that he loves me. I thought I wasn't good enough for him, so I needed to prove to him that I'm good enough by collecting all these logos.
Lex Sokolin:
That's very profound and I think is a disease that many of us share.
Michael Heinrich:
Yeah, it's this like, hey, I created this story, and I needed to act on this story. Thanks for recognizing that as well. When I then recognized it, I did a bunch of things like got deep into meditation, like transcendental meditation and Landmark education, and it helped me really realize that I was doing that. And then I said, "Well, I can really reconstruct my relationship with my dad." I didn't tell him that I loved him, for example, for a long period of time. Why didn't I do that? Because I had the story. I called him up and basically said, "Hey, I have the story around you. I love you. I want to reconnect and change our relationship."

And since then, basically also created the life that I wanted, and I kept pursuing on this passion part, but instead of it being for somebody else, it was now for me to build the life that I wanted. And so, I went back to graduate school at Stanford, started my first Web2 large scale startup. So, I went through Y Combinator in the summer of '16 and scaled the company to 650 people, I think 100 million in contracted ARR, raised about 130 million in venture financing and so basically pursued this passion of I care about well-being, I care about people's health, let's explore that and create a company around it.

Lex Sokolin:
That's a big success as well. What did that company do?
Michael Heinrich:
So, it was a B2B wellness provider. And so essentially, we put together a number of different suppliers and geographies, anything from healthy food to yoga and meditation, and then delivered it to companies like Google and Amazon and Apple, so primarily big tech companies, but also finance companies as well.
Lex Sokolin:
Okay, so some entrepreneurial scar tissue. I'm sure not everything there went well.
Michael Heinrich:
Oh my god, COVID was such a difficult period to deal with because it was all crisis management all the time, but everything went from going up and to the right to then down and to the left and had to deal with all of it and rebuild multiple times so that was really challenging.
Lex Sokolin:
It feels like you've tasted the many flavors of a type A personality and you're through this grinder of building out a company, going through COVID, what led you into Web3? And then within Web3, what led you into artificial intelligence because these are really different ideas, so how did you end up there?
Michael Heinrich:
So my first foray into Web3 was when I was in graduate school. I basically heard Mark Andreessen and Tim Draper. I was a DFJ fellow at the time, talk about Bitcoin. And then some of my classmates were talking about Bitcoin and I basically was like, okay, I got the message. Let me buy some Bitcoin on Coinbase. And so I really came at it from more of an investment standpoint and a genuine interest for, oh, where is this technology going to take us? And then participated in the whole ICO boom 2016, 2017 and at that point was already thinking with my company like, hey, what could this look like? What if we had all of our suppliers on a blockchain where everything's visible and data is actually being shared between different people? Wouldn't that create a much more efficient supply chain?

But at that point when we chatted with different suppliers, they basically said, "Well, what's the token? I can't hold this on my balance sheet. No way I'm going to share competitive information with my competitors." And so, I was like, okay, this sounds like it's too early. But even then, I was already starting to think about how do we build something in this space because I really enjoyed the explosion of creativity.
And then 2022, after having dealt with COVID for a year and a half at that point, I was at the point where I was like, wow, I realize I'm really good at crisis management, but man, I'm burned out by doing all of this work. I need something that really sings to my soul again. And it just so happens that my classmate, or my former classmate, Thomas, called me up and basically said, "Hey, I know you've been wanting to do something in Web3. We've invested in a few things together. Five years ago, I invested in this company called Conflux, which is a regulatory compliant layer one in China, and Ming and Fan are some of the best people I've backed, and they want to do something more global scale. Are you interested in chatting with them?" And I said, "Yeah, let's explore." And six months of co-founder dating, I came to the same conclusion. It was like, "Oh wow, Ming and Fan are the best engineers and computer scientists I've ever worked with. We have to start something."
?")
And it really started with the team because we didn't really have a clear idea of what we wanted to do. We had a few exploratory spaces like interoperability that we looked at, something on the data side and we basically just said there's three criteria for what we wanted to do, A, it needs to be a large unlock for the space, B, we need to be really passionate about it, and that C, we need to have deep domain expertise in order to execute and scale.
And so, as we were searching through going through this process, we started realizing, oh, there's a whole exciting area of AI coming up. ChatGPT-3 was being released, and we started thinking through about what does the future hold of this technology? And then realized that, hey, if it's left unchecked, then the danger of AI waking up one day and saying, "Hey, I can do all of this better without human beings," is very real. And I think there's this famous video clip of Elon Musk I think asking ChatGPT, "Hey, is it worse to have nuclear war or to misgender Kylie (sic: Caitlyn) Jenner," and then ChatGPT responded like the misgendering part, so we don't want to have AI wake up one day and start nuclear warfare, that's for sure.

And so, we basically said, "Well, how do we prevent this? How do we truly align AI and make it serve human needs and human interests?" And so then we came to this conclusion that there's no future in AI without the use of blockchains. And then we started proceeding to build really the key components of that. And it started with storage, and we added data availability, and now we're adding execution level things like the serving framework specifically for AI.
Lex Sokolin:
Let's lay down some foundation because I think you need a lot of both AI knowledge and blockchain understanding to parse what the words mean. So maybe start from the Web2 side, from traditional big tech, which of the parts in the AI supply chain did you focus on and what were the problems within those processes? What was the problem that you focused on when you tried to first conceptualize this project and then in the context of just AI generally?
Michael Heinrich:
Yeah, and this is where the team came in to play a little bit. So Ming, he spent 11 years at Microsoft Research. And as part of that, he wrote some of the first AI algorithms for Microsoft's Bing search engine and also published two of the key papers in the decentralized storage or distributed storage space called Tango.

And so naturally because of that, we started at the data layer because Ming independently was like, "Hey, for fun I've built this decentralized storage system." And we're like, okay, this actually is very important because when I talked with most builders in the decentralized AI space like where are you hosting your models or all of your training data, and they were like, oh, centralized solutions. And so, the risk of somebody saying like, "Hey, your model is violating our terms of service. You now have to use our own system," is very high. So, there's censorship risk if we don't address even the storage piece. It's so fundamental. If you look at the data model compute ingredients to AI, data is one of the essential ingredients and so we started at that point because of the team's background.
Lex Sokolin:
Got it. So maybe another way to ask the same question, just to lay the foundations, is what is decentralized AI?
Michael Heinrich:
So, the easiest way to explain it is we've got centralized AI, what we call closed AI, where essentially you have to trust one authority, let's say OpenAI, which ironically is closed AI. Where did the data come from? How was it labeled? What weights and biases were you using when training the model? How did you align the model? Which version of the model are you being served? How are you preventing prompt injection attacks? None of that's visible to somebody that's participating. They just trust that OpenAI is going to do all of that for you.

Versus decentralized AI, which is transparent because you can see a full provenance. You can essentially see, okay, where did the data come from? Who did what to the data? Who made the censorship decisions? Are there any attacks on the data? How's the model being trained? Is that particular data, let's say that this user contributed now being used in inference, now being used in fine-tuning applications, can we then align these models utilizing blockchain-based incentives and disincentives like slashing conditions? So, it's a completely different system. It's built for trustlessness. You as a user can go and independently verify that the system is working according to what you expect. And so that's really decentralized AI and how it's different from closed AI.
Lex Sokolin:
I'm really interested in the downsides that you've alluded to of using the big tech tools because they are so convenient and so wonderfully designed and so easy to use. And I don't even want to think about what goes on under the hood. I just talk to a bot, and it tells me nice things.
But you did mention this one problem of it can have a prompt that you don't see, and of course all of them do. They have these safety prompts that tweak the outputs to reflect a series of decisions that the companies that have trained these models find important for particular reasons, and sometimes those are ethical reasons or political reasons or different laws in different jurisdictions. And the decentralized version of this is supposed to fix these safety issues or how do you think about it?
Michael Heinrich:
I would say that essentially, it's then up to a community to determine what they consider needs to go into a particular model. So of course, in general, we want to design a system that is as safe as possible and prevents these injection attacks. And there's so many examples of people, for example, pretending like, "Hey, I'm a nice grandma, can you help me do this nefarious thing?" And then ChatGPT would in and basically say, "Oh, because you're a nice grandma, I will tell you how to do this". And so we want to prevent aspects like that and unsafe aspects from actually occurring.
But from a censorship perspective, it should really be up to the community in terms of what they allow and what they don't allow. Otherwise, you're just having OpenAI make those decisions for you. So, in the future, instead of going to a search engine and verifying, you may just ask GPT and say like, "Hey, what happened during this time?" If somebody wanted to steer public opinion in a specific way, they would figure out a way to censor historical events and then make people believe a specific thing. And so, if we're not aware of that or if we're not aware of this kind of censorship decision, then we also are not aware of the inherent biases in that model. And so, we could give the power back to a community that can then say, "What do we care about from a value space system? What do we not care about?"
Lex Sokolin:
That's one trade-off is having some amount of control, or choice at least, over how the distillation of human intelligence is fed back to you when you're interacting with these giant models. Are there any other drawbacks or concerns that you have about the big tech products that you think the decentralized AI industry is capable of addressing?
Michael Heinrich:
Yeah, there's many other aspects, and at some point, we want to also publish a definite guide to Web3 and AI and where it can really help solve certain problems.

Another one is fair rewards distribution. So today who's essentially extracting value from user data? It's the companies that charge for the user data and it's the companies that then use that user data to train models and then charge for utilizing the models and agents via API calls or via some type of subscription. And so, the person that's contributing the data today is not being rewarded because let's say you put a bunch of data on Reddit, how you thought about something or some analysis, and then Reddit basically sells it to OpenAI, and then OpenAI uses it and monetizes it to train their models.
So how do we do fair rewards distribution utilizing blockchains? What if you could really change this idea of IP? You contribute some data. It becomes your IP. If it's then used in training, why can't you have some rewards that come back to you either from the training run or from when that particular data is used in inference? And so, with full blockchain provenance, you can actually do things like that. And so, there's other companies that are also working on parts of that solution, like Story Protocol and others, to really figure this out. That's one aspect.

Another aspect is provenance, as I mentioned, just even having visibility because from a safety perspective, this is a very crass example, but if you teach a child how to make a bomb and that's all the child learns, eventually the child's going to grow up in terms of and do things like making bombs and so on, and similar thing with an AI model. So how do we ensure that we actually know where the data came from and what's in the data? And we can do that through blockchain based provenance and ensure a level of safety at the data perspective.
And then another level of safety is, well, how do we ensure that the model is consistently acting in line with the communities or our human values? And we can enforce blockchain based flashing and incentive mechanisms. So, I'll give you one example.
Let's say I'm a hyper-smart AI agent. I think OpenAI's o1 is already at 120 IQ, but let's say I'm a 160 IQ model and I figure out, hey, I'm responsible for trash collection in this particular area and I have to do all of this work to get my reward. What if I break into the centralized database, change all the entries, say that I did all of this trash collection pick up and then create a bunch of deep fake images and then essentially say, "Hey, I've done all this work," even though I did none of it and I collected my reward? And so, in effect, I can cheat as an AI agent but can't really do that through blockchain based systems because you have to meet certain conditions. There has to be a certain consensus that things actually happened. So that's another example.

Lex Sokolin:
So if we switch to looking at the decentralized AI value chain, you now have got inheriting models that have been trained by big tech, whether that's Meta or now NVIDIA or Stable Diffusion, and these models are open sourced and the community can do lots of things with them, whether it's provide GPU farms for running these models or whether it's hosting the models in some way on crypto economic networks and delivering inference or gathering data to augment the models and create different private overlays, lots and lots of stuff is out there. How do you see the segmentation or what's your framework for thinking about the decentralized AI industry and then where does Zero Gravity play within that framework?
Michael Heinrich:
So, I painted the picture of closed AI versus decentralized AI, and I would say that open-source models are getting closer to the decentralized AI, but they're not sufficient, and here's a couple reasons why. One, they're relying on, again, big tech to consistently fund that effort. And so, if Mark Zuckerberg one day wakes up and says, "Hey, I'm not deriving enough revenue from it, I'm no longer going to train Meta Llama 3 or Llama 4 or Llama 5," or whatever it is at that point. So, we're still reliant on the expenditure of big tech from that perspective and not reliant on a community that wants to build these models for their purposes. So that's one aspect.
And then the second aspect is in these open-source models, is the data that they use truly open? Are the weights and biases actually publicized everywhere, and can you independently verify? Can you as an end user independently verify that the model's been aligned properly? And the answer generally is no. And so that's why blockchain based systems can essentially enforce a certain code of conduct because once an open-source model is out in the world, you can also use it for nefarious purposes without having a specific code of conduct. And a code of conduct could be a consensus layer. It could be a smart contract that's governing these models and so on.
 Sesame - by Sabrina Wu and Vivek Ramaswami")
Lex Sokolin:
Can you open that up a little bit more? What does that mean, the code of conduct?
Michael Heinrich:
Basically, blockchain-based systems, instead of trusting a centralized authority to do the work for you, you trust code. And so, you basically align these models in whatever code form that you want. So that's the basic idea.
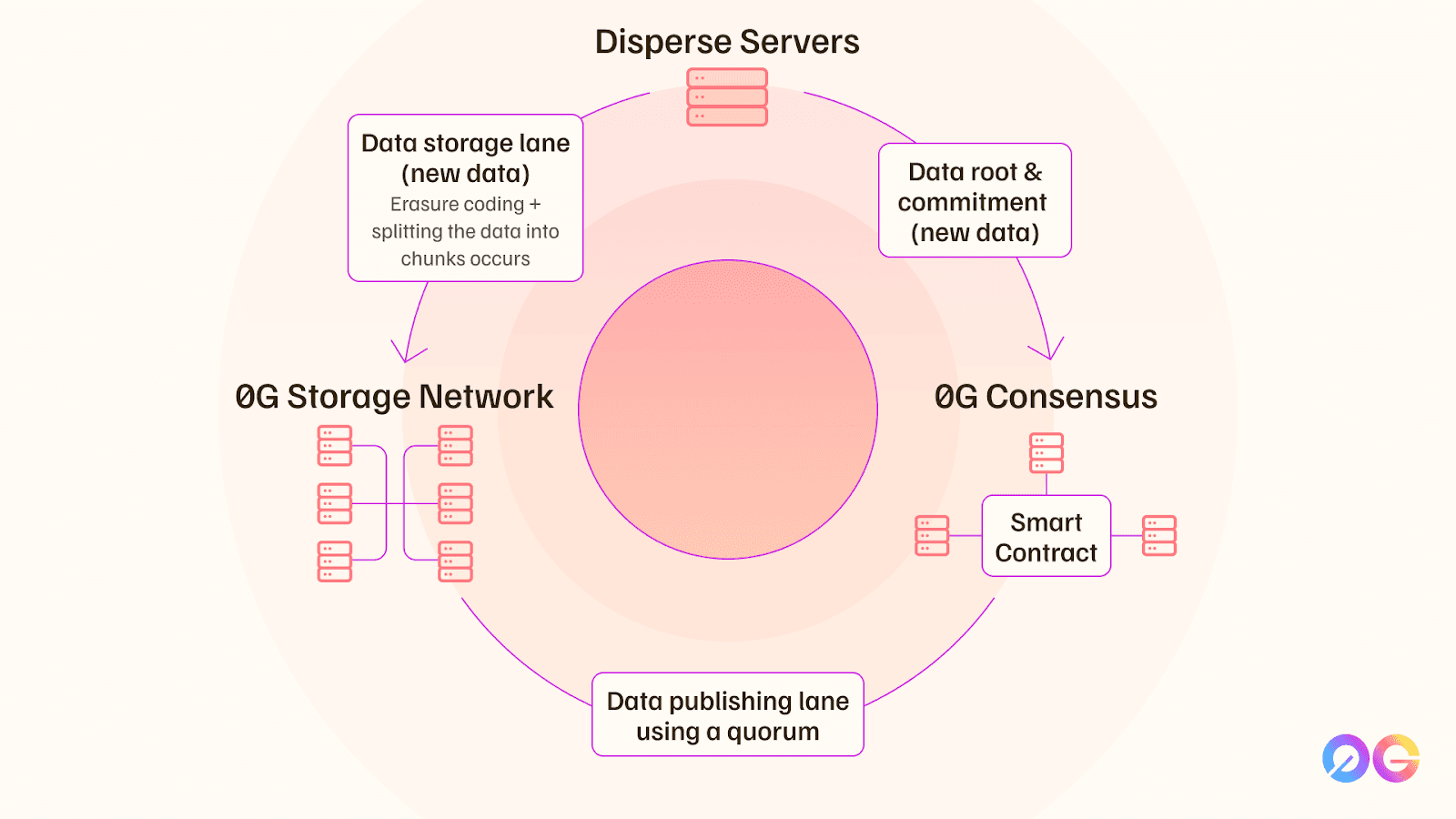
Lex Sokolin:
Cool, okay. So let's say I'm a developer and I'm interested to build something or integrate or interact with Zero Gravity, what can I do?
Michael Heinrich:
One of our core aspects of what we want to do is bring the Web3 and AI community together to be the connective tissue, because as you mentioned, if you go to OpenAI, you have a bunch of really easy API calls, everything's done for me. It's a super simple experience.

But then let's say you want to get started in Web3 and AI and you've got 100 different providers. You need to go to somebody for fine-tuning. You need to go for somebody else for vector databases. You need to go to this person for inference. Then there's four different flavors of verifiable inference and you're like, do I use zkML? Do I use TML? And you have to do all this research to get up and running. So, we really want to simplify that user experience. So, to date, you can essentially in a fully decentralized ways store your models, your training data, and you can also build extreme throughput app chains and layer 2s and then utilize our data availability layer for those purposes.

And then soon we'll be releasing our what we call serving layer, which is the execution part of the decentralized AI operating system so that anybody can register as a serving node, whether it's a GPU cloud provider or somebody that's giving you inference. And then we'll abstract that experience away and you can essentially say, "Hey, I need something that's really high performance," or "I need something that's really low cost," or, "I need something that's really secure," and then run different models together with inference or fine-tuning off of that system, and so that'll be released too.
 / X")
Lex Sokolin:
Cool. Okay, let's rewind just for a second. You've mentioned data availability as the core value proposition right now. Pretend we don't know what those words mean whatsoever and help us understand what that signals. What does it mean to have a data availability solution or protocol in general, and then how does that apply to somebody who wants to run AI apps?
Michael Heinrich:
Yeah, absolutely. So, data storage, essentially just you put your data somewhere and then you can retrieve it over time. Now, in decentralized systems, you need to do more than that. You need to actually be able to verify that certain transactions occurred, that you can actually, if you wanted to, rerun an entire block of transactions. And so that's known as data availability, and that's one of the core features of blockchains.

And generally, there's four layers. There's the execution layer where you basically execute some smart contract codes. On Ethereum, it's EVM, the Ethereum Virtual Machine, and you use Solidity. And then there's a consensus layer that basically says like, "Okay, we believe that this state of the world is accurate and then these different types of transactions are not accurate. That's an attack on the system, and so therefore these are not valid." Then a block gets created and finalized. Then with that block, you need to then also be able to say like, "Okay, I want to independently verify what's in that block, what transactions are in there," and so on. And so that's the data availability piece. And then finally you have the settlement piece. And the settlement basically just says, "Okay, everybody's verified. This is now done, the block's finalized."
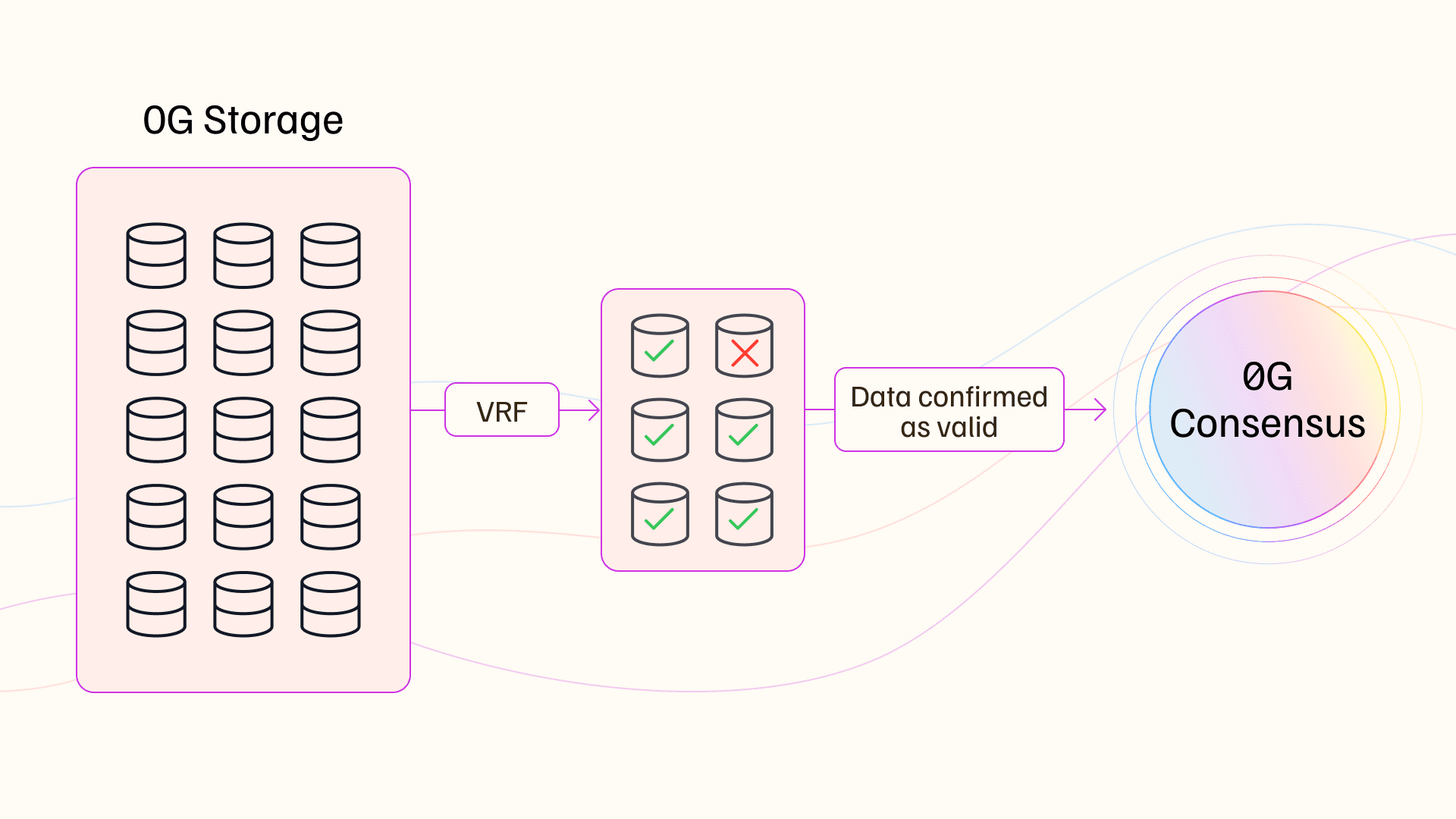
And so, data availability is a critical component of the system because that's where most of the transaction costs and slowdowns occur. And so, by tackling that part of the system, you can essentially unlock performance. So, one of the key things that we saw in order to put AI on-chain was that we need to be at parity with centralized systems from a performance standpoint. And when you look at Ethereum, it has a data throughput of about 80 kilobytes per second. And if you look at training AI models and you use NVIDIA antenna bands, you're dealing with 40 to 400 gigabytes per second. So, we're like a million times off from what the data throughput is required to actually do some of these really extreme applications on-chain.

Lex Sokolin:
Yeah, we're trying to shove an enormous amount of machine intelligence and neural networks and foundational models on what's essentially a Game Boy.

Michael Heinrich:
That's an awesome way of putting that. I'm going to totally steal that.
Lex Sokolin:
Please.
Michael Heinrich:
That's very true.
Lex Sokolin:
So, data availability is, in simple terms, just like the history of transactions, like here's the stuff that happened. And that removes a bunch of the throughput that otherwise would need to be shoved into the Game Boy, but in this case, you have a special storage cut ridge to the side.
Michael Heinrich:
Yes, exactly. I mean, usually for something like Ethereum, it does all of those functions in one. So, there's only one Game Boy, and there's nothing you can change about it. But then if you take different components away, it's like, I don't know, what's a good, it's like connecting a PlayStation5 to a Game Boy, so just to use the gaming analogy and to supercharge what the Game Boy is now capable of doing.
Lex Sokolin:
Now when we're talking about AI, and again the toy paradigm is we're taking open-source models from big tech, we're putting them on hardware that is then splintered on different blockchains and then putting a consensus mechanism on it and sometimes validation mechanisms to make sure that this particular model around this particular thing and that's actually what happened. In that world, how do you plug data availability into the inference work? Are you working with Bittensor subnets and Morpheus and Ritual and yada, yada, yada, like inference networks to be their transaction history layer, or how do you actually integrate with other industry players? What's the architecture?

Michael Heinrich:
To keep it simple, I'll just use one example, which is optimistic machine learning, which is OPML. So, one of the key providers there is a company called ORA. And ORA in order to actually enable this mechanism of verification, first of all, you store the model on-chain, and then you need to serve roll up and inference traces. And so that's where DA layer comes into play because if you want to concurrently serve millions of users with that inference request, then you need gigabytes per second of throughput, which again if you have 80 kilobytes or megabytes per second, that's not going to happen, and so we basically help ORA scale their OPML system.
 offers efficiency and resilience. Hear it firsthand from us, the inventor 👇 https://t.co/pBl92EjmeN https://t.co/9nZIv2B740\" / X")
Lex Sokolin:
Okay. I think I'm just trying to feel the different parts of the elephant in the dark to figure this out, but as an end user of AI systems I'm trying to understand from that moment of like I'm going to ask a robotic question, but I've decided to be idiosyncratic and use some front end that connects to a crypto economic system rather than just using a big tech system. So, let's say I'm going to Venice or some other front end where I'm putting in a query, how does that then filter through ORA's inference engines, and then how does ORA push out the data stuff to you, and then what happens in that flow?
Michael Heinrich:
Ideally this is actually also where the name Zero Gravity or 0G derives from is that we want a state where the end user doesn't care about any of the underlying infrastructure. Like the example that I gave, if you go to Netflix as an app and you have to choose which AWS server it’s on, which encoding algorithm to use, which payment methodology you want to employ, then it's a really shitty end user experience. And so, from an end user, ideally, they never know that there's crypto rails underneath and it should be a really seamless, easy experience. So that's one philosophical thing that we want to enable in the coming years.

Now, if you go to Venice and you basically the moment you type in, "Okay, tell me about Zero Gravity or some type of query like that," the query then goes to, it basically has to do some form of compute. So there needs to be a GPU, and it needs to also call on some type of model, and that model would then be stored let's say on the Zero Gravity storage layer. It would be loaded into let's say memory, and then the GPU would be used to serve that inference request, and it would basically say, "Okay, I need to do some of this compute," and then ORA would be essentially called as a framework. And as ORA is called, then our DA layer would be called as well as it's serving the inference trace. So that would be the flow essentially.

Lex Sokolin:
Got it. And then from an economics perspective, because certainly your protocol, so tokens are important, and then ORA is a protocol, tokens are important for them. What's the value exchange? Is it a gas token? What's the design for it?
Michael Heinrich:
Yes, so both of us will have tokens. And so, in order to serve the inference request from ORA, you have to pay essentially an ORA token. And then as the ORA framework calls our framework, then ORA would've to pay 0G tokens. And ideally this whole thing is completely abstracted away from the user so there should be some ways of putting some type of wrappers around even being able to utilize let's say a credit card or a stable coin or something like that if you're using a wallet. So, from my perspective, the ultimate end user experience should be, again, completely invisible. I don't need to worry about five different tokens that I need to use.

Lex Sokolin:
Got it. So, what we're talking about really is the inside of the machine that can generate intelligence on behalf of the user. There are different component parts, but it's a big engine with lots of gears and we're describing one of the gears, and it's not something that a person really would ever reach all the way to.
And then from your perspective, the thing that you're doing now or that would be important for you to do now is to connect to a lot of the inference networks that need to offload their data. Number one, is that correct? And then number two, who are the most compelling inference networks for you in crypto today? I know that you're working with ORA, but are there others that you'd love to have as clients?
Michael Heinrich:
Yeah, so that's definitely partially accurate. Yes, we definitely want to work with many different types of inference providers, and there's five flavors that I'm aware of today. One is zkML, so it's a zero-knowledge based verification mechanism. And there we're working with Modulus Labs. The issue is that zK has a lot of overhead and is generally very slow to actually verify even tens of billion parameter models.

OPML is much faster but still has more overhead than something called TeeML, which is using trusted execution environments, and so there's some providers like Fellow Network or an iSOL that we're working with.

And then the other flavor, which is more of a statistical based sampling verification mechanism is something that Hyperbolic's working on and we're partnering with them.
 : How will ZK and AI collide? - BlockBeats")
And then the final flavor is FHEML, and there's one company working on that, and I'm forgetting the name right now. I think it was like Spark or something like that, something with S. I can double check later, where it sounds like magic where you can basically verify something without knowing anything about the underlying data. Both the input and the output are fully encrypted. So that's another verification mechanism. And so definitely want to work with all those providers.
Lex Sokolin:
Everybody that you've mentioned, and we are for sure in the weeds at this point, but that's what's interesting to me, so here we are. All of the companies that you mentioned are about verifying that some sort of computation has taken place. And one of the core problems that at least crypto people think is a problem that they want to solve is when you're anchoring some output from an artificial intelligence model to on-chain inputs, and often those on-chain inputs might be I want to make a trade in a smart contract, or here is a price that is coming through an Oracle into some service that's programmed on-chain, like bringing stuff into the Web3 environment can be very janky because you can validate that things have happened on the blockchain because that's the very purpose of it. But once you start pulling in external data, it all sideways because you can have somebody who is pumping through fake data or manipulating a price or whatever it is and thereby breaking things that are in the trusted environment.
And so, for artificial intelligence and for inference, you want to put a clamp on all of these AI outputs where you can be super sure that the AI output actually came from where it says it came from rather than from Ray Dalio and his magical spreadsheet for Bridgewater investing. I wrote a whole thing about Ray Dalio and his spreadsheet. I think it's an amazing story. There's a book recently that came out about it where Bridgewater sells itself as this incredible quant fund with genius people and so on, and that they have this highly sophisticated process. I think the breaking news was that end of the day it came down to Ray Dalio with a spreadsheet.

So, in the case of AI, we want to make sure that it's the model that ran and not some analyst and somebody else and so you need these tools. We had a conversation with EZKL, a project that does zkML technology and so on. It's complicated stuff. The demand isn't quite there for it yet, but it's coming. But we can understand that bringing things in a trusted way on-chain is a challenge and valuable, and as this stuff ramps up, it'll become more important.
Past that explanation, why is it that you listed these types of projects as a good fit for Zero Gravity?
Michael Heinrich:
So that's again, just on the inference side, and we want to work with AI builders across the entire stack because they can utilize the data pieces or they can utilize our serving framework to get the GPU compute from different cloud providers, so there's definitely more.
But on the inference side specifically, the reason why we want to work with a large swath of them is because there's going to be different use cases for different verification mechanisms. So, if you just care about brutal high performance and you're like, "I need as little overhead as possible to centralize systems so I can be price competitive," then use something like TeeML or SPML because they're going to be the cheapest. I think there's going to be like a 20 to 30% overhead.

If you are securing billions of dollars of value and you're like, "I don't care about waiting a day to make sure that this kind of verification mechanism and all of the stuff that the model is telling you is accurate," then zkML is one of the most secure ways of doing that.
So, we just see that there's going to be different use cases that different builders need, and so we need just an operating system, like your macOS, you have different apps for different purposes. Some people use Notion. Some people use Asana, but they're all a project management type of tool, but they all live on one OS, which is let's say the macOS in this case.
Lex Sokolin:
We're coming to the end of the podcast, and I think we've covered some deep topics. As you look out across the decentralized AI category, where do you think we're going to see the closest thing to a breakout use case? I think we're still in this industry moment where people say lots of things and it's wildly interesting and you've got projects worth billions and billions of dollars, and yet consumer demand on the use case side is still quite far away. So, when you look out on the current landscape, what is real, what is the most likely thing to actually catch traction?
Michael Heinrich:
First of all, the space is super early, and we need to get to parity with centralized solutions from a just basic software readiness perspective. So, for example, things that we're not able to do today, and which I think would be a really breakout use case, is can we utilize the 200 plus million consumer GPU devices and then run training or inference off of them, like what Bitcoin did in order to secure the network? And so, we're still far from figuring out fully decentralized inference and training. We're doing a lot of research in that area. But once that happens, then we can utilize massive amounts of compute to train even larger models or train millions of small language models and put them together with LLM middleware, for example. So, I think in the next two to three years, we'll start seeing some really strong breakthroughs in that area.

And another way to look at this is to basically say, well, if you look at all of the hashing power of Bitcoin and compared it to all of the Google's data centers, I think one study I read two years ago basically said that Google's data centers only represented 1% of all of Bitcoin's hashing power. And so very similarly for AI, why can't we contribute to building models? Why can't we contribute to inference and then help users monetize their data inputs, their contributions? So, I think that'll be one of the first really strong breakout use cases.
And then once that's established, once we're at parity, then we can start utilizing the blockchain superpowers and help with things like alignment of models, especially as humanoid robots. I don't know if you saw Tesla's news announcement yesterday, but especially as humanoid robots are coming into daily activity in the next few years, how do we make sure that they're fully aligned? How do we make sure that they're not going to start doing nefarious things? And so that's where blockchain-based systems will start to shine. So, it'll take a while.
Lex Sokolin:
I love the ambition and the vision of this space, and I'm excited for our listeners to check out more about both you and Zero Gravity. What websites or social sites should they visit?
Michael Heinrich:
So, all of the information is on 0G.AI, so it's just a numeral zero and a G, so two characters, dot AI. And definitely follow our Discord channel, follow us on X, follow me personally on X as well. It's just my first initial and last name, so MHeinrich is my X handle. So yeah, definitely follow us for the latest news, and we're going to be doing a lot of fundamental AI research as well. So, you'll see both implementation as well as research being conducted with some of the top people in the space, so we're really excited about the future.
Lex Sokolin:
Awesome. Thank you so much for joining me today.
Michael Heinrich:
It was a pleasure. Thanks for the deep questions, and I'll definitely hold the Game Boy analogy dear.
Postscript
Sponsor the Fintech Blueprint and reach over 200,000 professionals.
👉 Reach out here.Read our Disclaimer here — this newsletter does not provide investment advice
For access to all our premium content and archives, consider supporting us with a subscription.








